 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupervised Understanding of Word Embeddings
Jun 23, 2020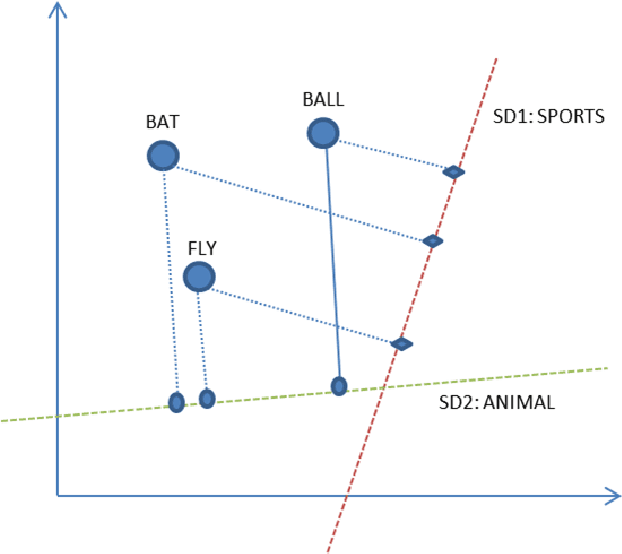

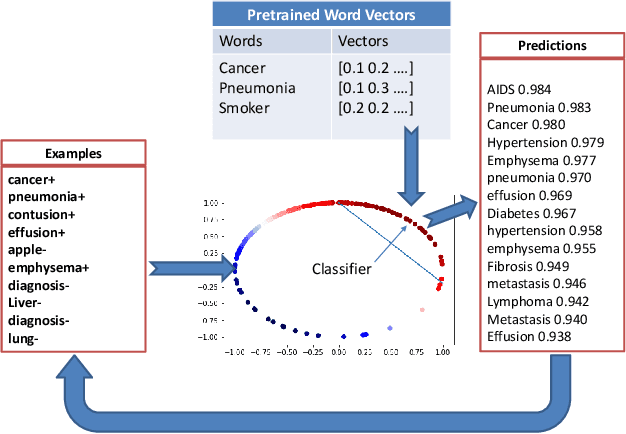

Pre-trained word embeddings are widely used for transfer learning in natural language processing. The embeddings are continuous and distributed representations of the words that preserve their similarities in compact Euclidean spaces. However, the dimensions of these spaces do not provide any clear interpretation. In this study, we have obtained supervised projections in the form of the linear keyword-level classifiers on word embeddings. We have shown that the method creates interpretable projections of original embedding dimensions. Activations of the trained classifier nodes correspond to a subset of the words in the vocabulary. Thus, they behave similarly to the dictionary features while having the merit of continuous value output. Additionally, such dictionaries can be grown iteratively with multiple rounds by adding expert labels on top-scoring words to an initial collection of the keywords. Also, the same classifiers can be applied to aligned word embeddings in other languages to obtain corresponding dictionaries. In our experiments, we have shown that initializing higher-order networks with these classifier weights gives more accurate models for downstream NLP tasks. We further demonstrate the usefulness of supervised dimensions in revealing the polysemous nature of a keyword of interest by projecting it's embedding using learned classifiers in different sub-spaces.