 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGeneralized Resubstitution for Classification Error Estimation
Oct 23, 2021
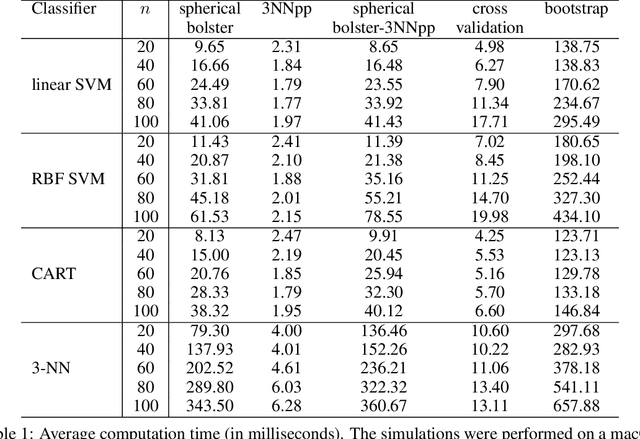
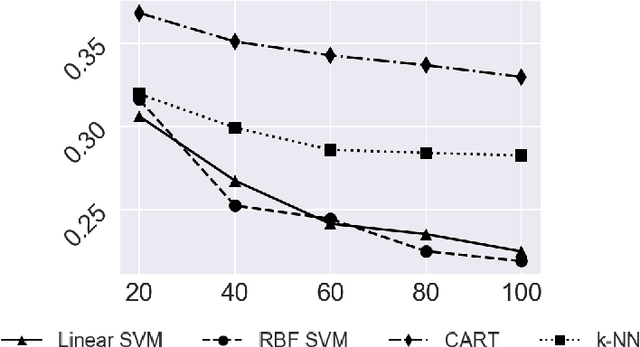

We propose the family of generalized resubstitution classifier error estimators based on empirical measures. These error estimators are computationally efficient and do not require re-training of classifiers. The plain resubstitution error estimator corresponds to choosing the standard empirical measure. Other choices of empirical measure lead to bolstered, posterior-probability, Gaussian-process, and Bayesian error estimators; in addition, we propose bolstered posterior-probability error estimators as a new family of generalized resubstitution estimators. In the two-class case, we show that a generalized resubstitution estimator is consistent and asymptotically unbiased, regardless of the distribution of the features and label, if the corresponding generalized empirical measure converges uniformly to the standard empirical measure and the classification rule has a finite VC dimension. A generalized resubstitution estimator typically has hyperparameters that can be tuned to control its bias and variance, which adds flexibility. Numerical experiments with various classification rules trained on synthetic data assess the thefinite-sample performance of several representative generalized resubstitution error estimators. In addition, results of an image classification experiment using the LeNet-5 convolutional neural network and the MNIST data set demonstrate the potential of this class of error estimators in deep learning for computer vision.
Comparison of Classification Algorithms Towards Subject-Specific and Subject-Independent BCI
Jan 05, 2021



Motor imagery brain computer interface designs are considered difficult due to limitations in subject-specific data collection and calibration, as well as demanding system adaptation requirements. Recently, subject-independent (SI) designs received attention because of their possible applicability to multiple users without prior calibration and rigorous system adaptation. SI designs are challenging and have shown low accuracy in the literature. Two major factors in system performance are the classification algorithm and the quality of available data. This paper presents a comparative study of classification performance for both SS and SI paradigms. Our results show that classification algorithms for SS models display large variance in performance. Therefore, distinct classification algorithms per subject may be required. SI models display lower variance in performance but should only be used if a relatively large sample size is available. For SI models, LDA and CART had the highest accuracy for small and moderate sample size, respectively, whereas we hypothesize that SVM would be superior to the other classifiers if large training sample-size was available. Additionally, one should choose the design approach considering the users. While the SS design sound more promising for a specific subject, an SI approach can be more convenient for mentally or physically challenged users.
Learning Patterns in Imaginary Vowels for an Intelligent Brain Computer Interface Design
Oct 17, 2020



Technology advancements made it easy to measure non-invasive and high-quality electroencephalograph (EEG) signals from human's brain. Hence, development of robust and high-performance AI algorithms becomes crucial to properly process the EEG signals and recognize the patterns, which lead to an appropriate control signal. Despite the advancements in processing the motor imagery EEG signals, the healthcare applications, such as emotion detection, are still in the early stages of AI design. In this paper, we propose a modular framework for the recognition of vowels as the AI part of a brain computer interface system. We carefully designed the modules to discriminate the English vowels given the raw EEG signals, and meanwhile avoid the typical issued with the data-poor environments like most of the healthcare applications. The proposed framework consists of appropriate signal segmentation, filtering, extraction of spectral features, reducing the dimensions by means of principle component analysis, and finally a multi-class classification by decision-tree-based support vector machine (DT-SVM). The performance of our framework was evaluated by a combination of test-set and resubstitution (also known as apparent) error rates. We provide the algorithms of the proposed framework to make it easy for future researchers and developers who want to follow the same workflow.