 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSchema Independent Relational Learning
Nov 06, 2017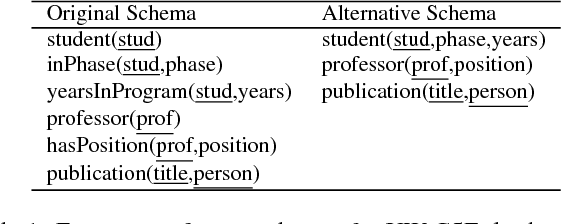
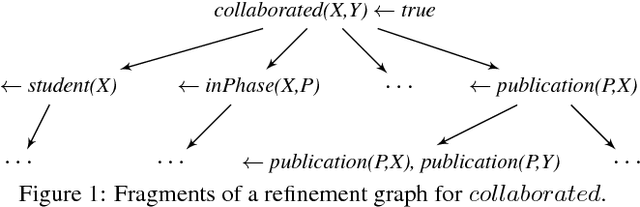

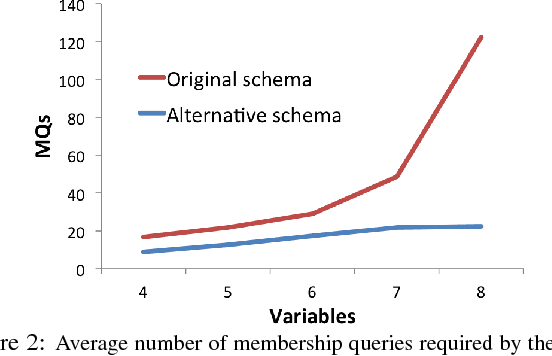
Learning novel concepts and relations from relational databases is an important problem with many applications in database systems and machine learning. Relational learning algorithms learn the definition of a new relation in terms of existing relations in the database. Nevertheless, the same data set may be represented under different schemas for various reasons, such as efficiency, data quality, and usability. Unfortunately, the output of current relational learning algorithms tends to vary quite substantially over the choice of schema, both in terms of learning accuracy and efficiency. This variation complicates their off-the-shelf application. In this paper, we introduce and formalize the property of schema independence of relational learning algorithms, and study both the theoretical and empirical dependence of existing algorithms on the common class of (de) composition schema transformations. We study both sample-based learning algorithms, which learn from sets of labeled examples, and query-based algorithms, which learn by asking queries to an oracle. We prove that current relational learning algorithms are generally not schema independent. For query-based learning algorithms we show that the (de) composition transformations influence their query complexity. We propose Castor, a sample-based relational learning algorithm that achieves schema independence by leveraging data dependencies. We support the theoretical results with an empirical study that demonstrates the schema dependence/independence of several algorithms on existing benchmark and real-world datasets under (de) compositions.