 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Over Dirty Data Without Cleaning
Apr 05, 2020


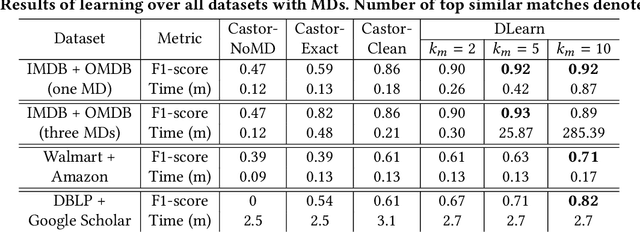
Real-world datasets are dirty and contain many errors. Examples of these issues are violations of integrity constraints, duplicates, and inconsistencies in representing data values and entities. Learning over dirty databases may result in inaccurate models. Users have to spend a great deal of time and effort to repair data errors and create a clean database for learning. Moreover, as the information required to repair these errors is not often available, there may be numerous possible clean versions for a dirty database. We propose DLearn, a novel relational learning system that learns directly over dirty databases effectively and efficiently without any preprocessing. DLearn leverages database constraints to learn accurate relational models over inconsistent and heterogeneous data. Its learned models represent patterns over all possible clean instances of the data in a usable form. Our empirical study indicates that DLearn learns accurate models over large real-world databases efficiently.
Schema Independent Relational Learning
Nov 06, 2017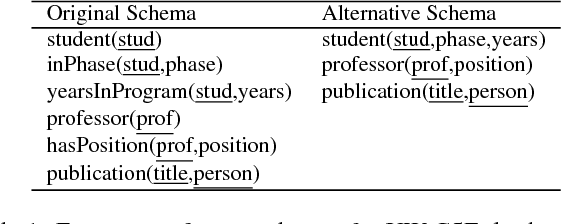
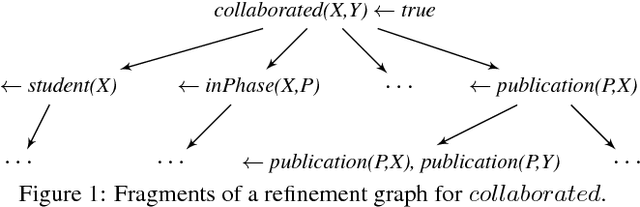

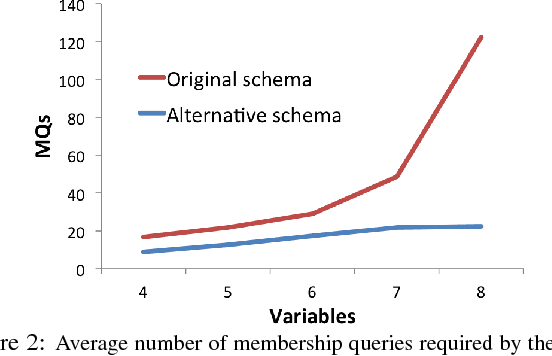
Learning novel concepts and relations from relational databases is an important problem with many applications in database systems and machine learning. Relational learning algorithms learn the definition of a new relation in terms of existing relations in the database. Nevertheless, the same data set may be represented under different schemas for various reasons, such as efficiency, data quality, and usability. Unfortunately, the output of current relational learning algorithms tends to vary quite substantially over the choice of schema, both in terms of learning accuracy and efficiency. This variation complicates their off-the-shelf application. In this paper, we introduce and formalize the property of schema independence of relational learning algorithms, and study both the theoretical and empirical dependence of existing algorithms on the common class of (de) composition schema transformations. We study both sample-based learning algorithms, which learn from sets of labeled examples, and query-based algorithms, which learn by asking queries to an oracle. We prove that current relational learning algorithms are generally not schema independent. For query-based learning algorithms we show that the (de) composition transformations influence their query complexity. We propose Castor, a sample-based relational learning algorithm that achieves schema independence by leveraging data dependencies. We support the theoretical results with an empirical study that demonstrates the schema dependence/independence of several algorithms on existing benchmark and real-world datasets under (de) compositions.
AutoMode: Relational Learning With Less Black Magic
Oct 03, 2017
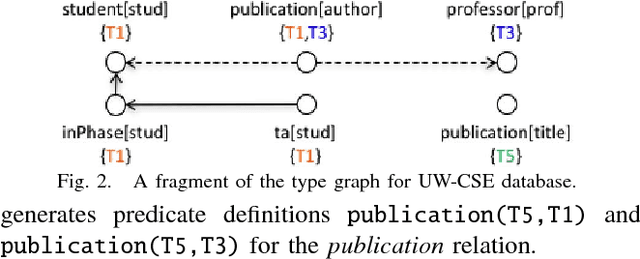

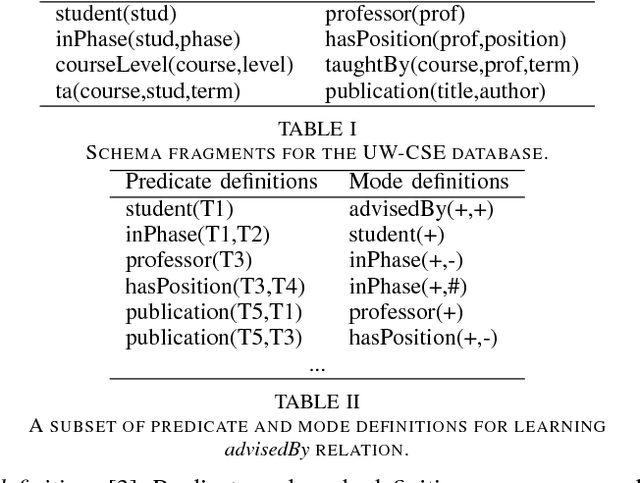
Relational databases are valuable resources for learning novel and interesting relations and concepts. Relational learning algorithms learn the Datalog definition of new relations in terms of the existing relations in the database. In order to constraint the search through the large space of candidate definitions, users must tune the algorithm by specifying a language bias. Unfortunately, specifying the language bias is done via trial and error and is guided by the expert's intuitions. Hence, it normally takes a great deal of time and effort to effectively use these algorithms. In particular, it is hard to find a user that knows computer science concepts, such as database schema, and has a reasonable intuition about the target relation in special domains, such as biology. We propose AutoMode, a system that leverages information in the schema and content of the database to automatically induce the language bias used by popular relational learning systems. We show that AutoMode delivers the same accuracy as using manually-written language bias by imposing only a slight overhead on the running time of the learning algorithm.