 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProtein Language Model Embeddings Improve Generalization of Implicit Transfer Operators
Feb 11, 2026Molecular dynamics (MD) is a central computational tool in physics, chemistry, and biology, enabling quantitative prediction of experimental observables as expectations over high-dimensional molecular distributions such as Boltzmann distributions and transition densities. However, conventional MD is fundamentally limited by the high computational cost required to generate independent samples. Generative molecular dynamics (GenMD) has recently emerged as an alternative, learning surrogates of molecular distributions either from data or through interaction with energy models. While these methods enable efficient sampling, their transferability across molecular systems is often limited. In this work, we show that incorporating auxiliary sources of information can improve the data efficiency and generalization of transferable implicit transfer operators (TITO) for molecular dynamics. We find that coarse-grained TITO models are substantially more data-efficient than Boltzmann Emulators, and that incorporating protein language model (pLM) embeddings further improves out-of-distribution generalization. Our approach, PLaTITO, achieves state-of-the-art performance on equilibrium sampling benchmarks for out-of-distribution protein systems, including fast-folding proteins. We further study the impact of additional conditioning signals -- such as structural embeddings, temperature, and large-language-model-derived embeddings -- on model performance.
An audiovisual and contextual approach for categorical and continuous emotion recognition in-the-wild
Jul 10, 2021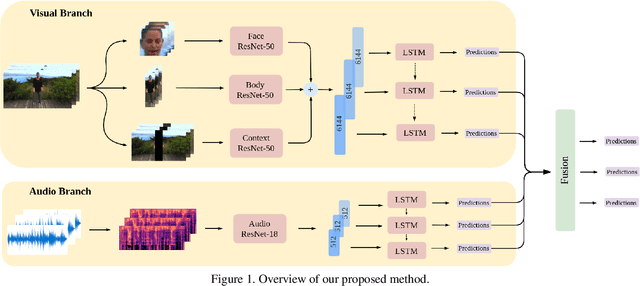
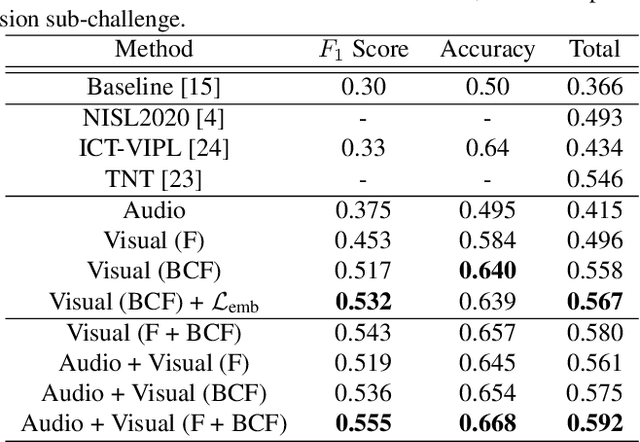
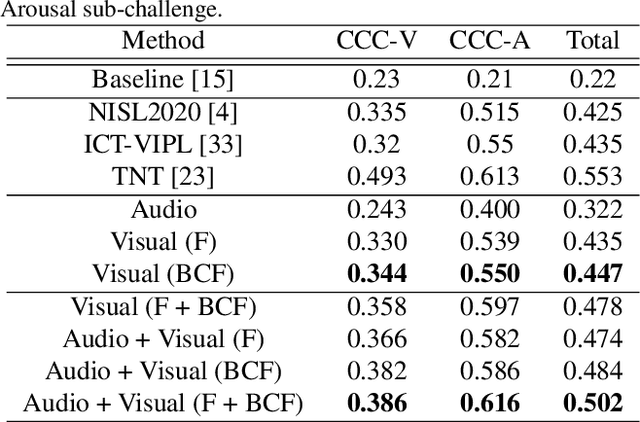
In this work we tackle the task of video-based audio-visual emotion recognition, within the premises of the 2nd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW). Poor illumination conditions, head/body orientation and low image resolution constitute factors that can potentially hinder performance in case of methodologies that solely rely on the extraction and analysis of facial features. In order to alleviate this problem, we leverage bodily as well as contextual features, as part of a broader emotion recognition framework. We choose to use a standard CNN-RNN cascade as the backbone of our proposed model for sequence-to-sequence (seq2seq) learning. Apart from learning through the RGB input modality, we construct an aural stream which operates on sequences of extracted mel-spectrograms. Our extensive experiments on the challenging and newly assembled Affect-in-the-wild-2 (Aff-Wild2) dataset verify the superiority of our methods over existing approaches, while by properly incorporating all of the aforementioned modules in a network ensemble, we manage to surpass the previous best published recognition scores, in the official validation set. All the code was implemented using PyTorch\footnote{\url{https://pytorch.org/}} and is publicly available\footnote{\url{https://github.com/PanosAntoniadis/NTUA-ABAW2021}}.
Exploiting Emotional Dependencies with Graph Convolutional Networks for Facial Expression Recognition
Jun 07, 2021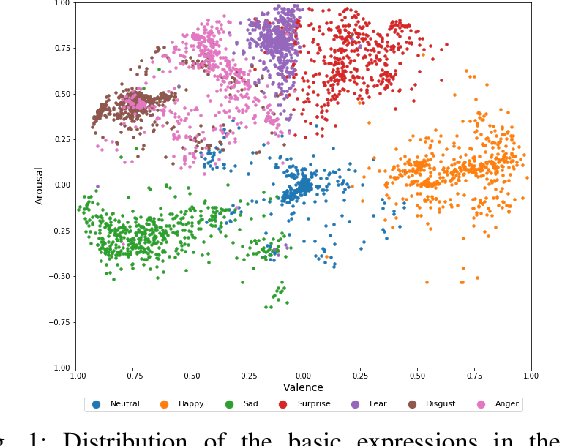
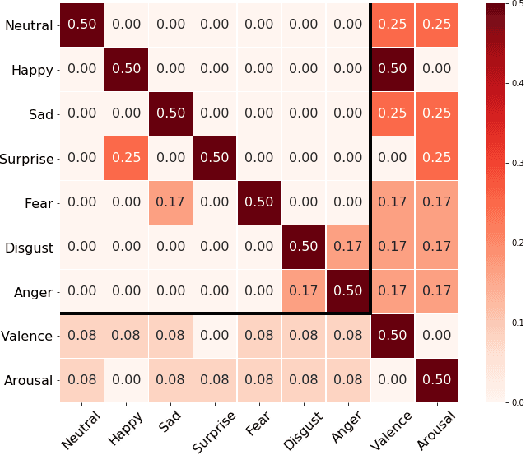
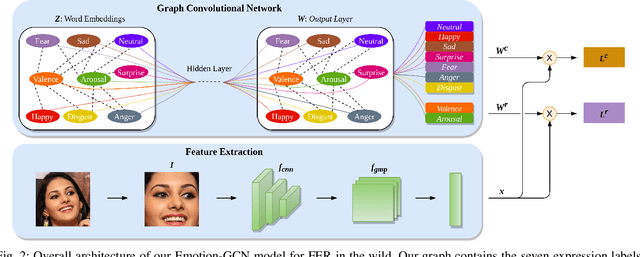
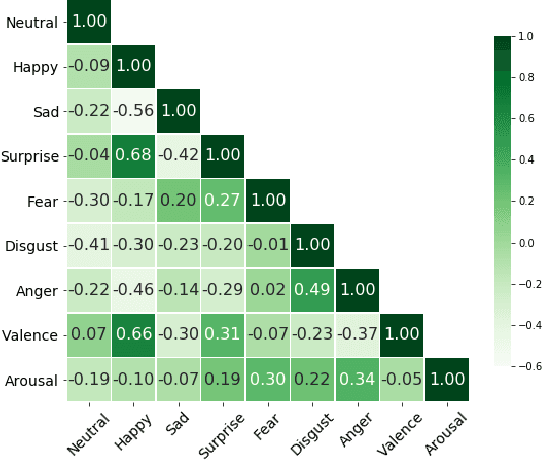
Over the past few years, deep learning methods have shown remarkable results in many face-related tasks including automatic facial expression recognition (FER) in-the-wild. Meanwhile, numerous models describing the human emotional states have been proposed by the psychology community. However, we have no clear evidence as to which representation is more appropriate and the majority of FER systems use either the categorical or the dimensional model of affect. Inspired by recent work in multi-label classification, this paper proposes a novel multi-task learning (MTL) framework that exploits the dependencies between these two models using a Graph Convolutional Network (GCN) to recognize facial expressions in-the-wild. Specifically, a shared feature representation is learned for both discrete and continuous recognition in a MTL setting. Moreover, the facial expression classifiers and the valence-arousal regressors are learned through a GCN that explicitly captures the dependencies between them. To evaluate the performance of our method under real-world conditions we train our models on AffectNet dataset. The results of our experiments show that our method outperforms the current state-of-the-art methods on discrete FER.