 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComboNet: Combined 2D & 3D Architecture for Aorta Segmentation
Jun 09, 2020
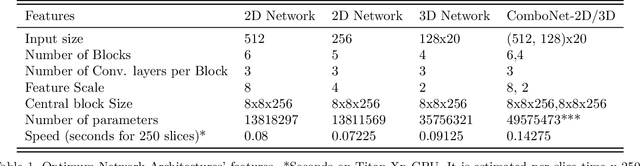
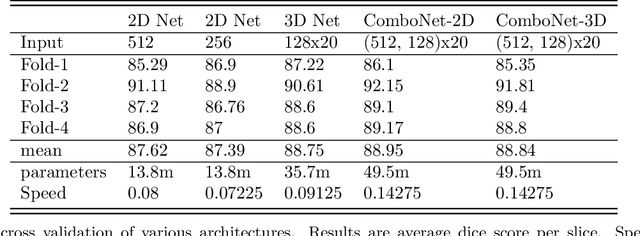
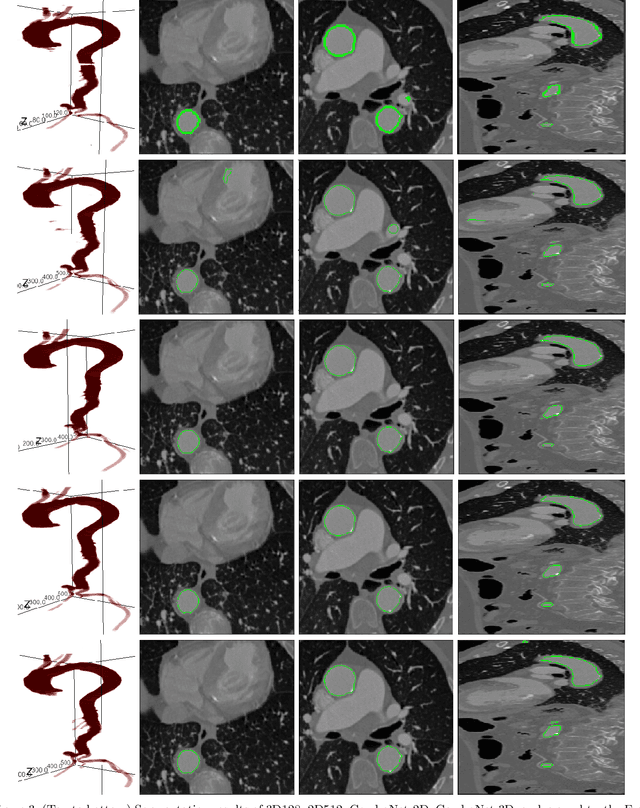
3D segmentation with deep learning if trained with full resolution is the ideal way of achieving the best accuracy. Unlike in 2D, 3D segmentation generally does not have sparse outliers, prevents leakage to surrounding soft tissues, at the very least it is generally more consistent than 2D segmentation. However, GPU memory is generally the bottleneck for such an application. Thus, most of the 3D segmentation applications handle sub-sampled input instead of full resolution, which comes with the cost of losing precision at the boundary. In order to maintain precision at the boundary and prevent sparse outliers and leakage, we designed ComboNet. ComboNet is designed in an end to end fashion with three sub-network structures. The first two are parallel: 2D UNet with full resolution and 3D UNet with four times sub-sampled input. The last stage is the concatenation of 2D and 3D outputs along with a full-resolution input image which is followed by two convolution layers either with 2D or 3D convolutions. With ComboNet we have achieved $92.1\%$ dice accuracy for aorta segmentation. With Combonet, we have observed up to $2.3\%$ improvement of dice accuracy as opposed to 2D UNet with the full-resolution input image.