 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Semi-Supervised Generalized-Linear-Regression with applications to Deep learning
Feb 19, 2023We present a methodology for using unlabeled data to design semi supervised learning (SSL) methods that improve the prediction performance of supervised learning for regression tasks. The main idea is to design different mechanisms for integrating the unlabeled data, and include in each of them a mixing parameter $\alpha$, controlling the weight given to the unlabeled data. Focusing on Generalized-Linear-Models (GLM), we analyze the characteristics of different mixing mechanisms, and prove that in all cases, it is inevitably beneficial to integrate the unlabeled data with some non-zero mixing ratio $\alpha>0$, in terms of predictive performance. Moreover, we provide a rigorous framework for estimating the best mixing ratio $\alpha^*$ where mixed-SSL delivers the best predictive performance, while using the labeled and the unlabeled data on hand. The effectiveness of our methodology in delivering substantial improvement compared to the standard supervised models, under a variety of settings, is demonstrated empirically through extensive simulation, in a manner that supports the theoretical analysis. We also demonstrate the applicability of our methodology (with some intuitive modifications) in improving more complex models such as deep neural networks, in a real-world regression tasks.
Semi-Supervised Empirical Risk Minimization: When can unlabeled data improve prediction
Sep 01, 2020
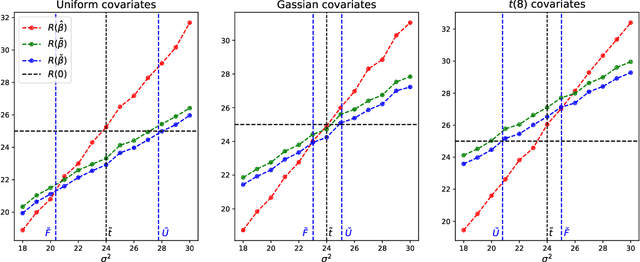

We present a general methodology for using unlabeled data to design semi supervised learning (SSL) variants of the Empirical Risk Minimization (ERM) learning process. Focusing on generalized linear regression, we provide a careful treatment of the effectiveness of the SSL to improve prediction performance. The key ideas are carefully considering the null model as a competitor, and utilizing the unlabeled data to determine signal-noise combinations where the SSL outperforms both the ERM learning and the null model. In the special case of linear regression with Gaussian covariates, we show that the previously suggested semi-supervised estimator is in fact not capable of improving on both the supervised estimator and the null model simultaneously. However, the new estimator presented in this work, can achieve an improvement of $O(1/n)$ term over both competitors simultaneously. On the other hand, we show that in other scenarios, such as non-Gaussian covariates, misspecified linear regression, or generalized linear regression with non-linear link functions, having unlabeled data can derive substantial improvement in prediction by applying our suggested SSL approach. Moreover, it is possible to identify the usefulness of the SSL, by using the dedicated formulas we establish throughout this work. This is shown empirically through extensive simulations.