 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFairHome: A Fair Housing and Fair Lending Dataset
Sep 09, 2024We present a Fair Housing and Fair Lending dataset (FairHome): A dataset with around 75,000 examples across 9 protected categories. To the best of our knowledge, FairHome is the first publicly available dataset labeled with binary labels for compliance risk in the housing domain. We demonstrate the usefulness and effectiveness of such a dataset by training a classifier and using it to detect potential violations when using a large language model (LLM) in the context of real-estate transactions. We benchmark the trained classifier against state-of-the-art LLMs including GPT-3.5, GPT-4, LLaMA-3, and Mistral Large in both zero-shot and few-shot contexts. Our classifier outperformed with an F1-score of 0.91, underscoring the effectiveness of our dataset.
Out-Of-Bag Anomaly Detection
Sep 20, 2020

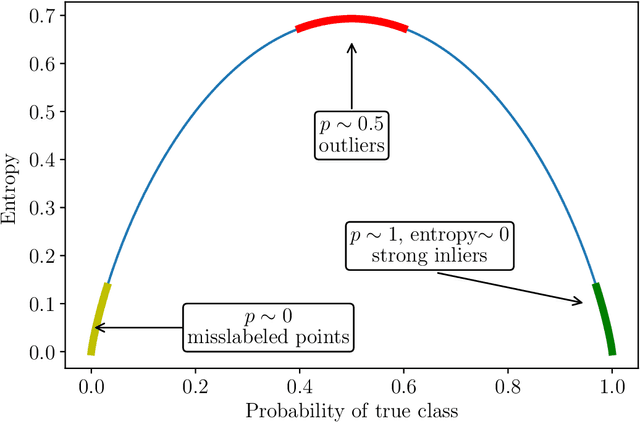
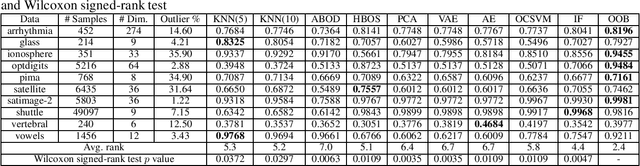
Data anomalies are ubiquitous in real world datasets, and can have an adverse impact on machine learning (ML) systems, such as automated home valuation. Detecting anomalies could make ML applications more responsible and trustworthy. However, the lack of labels for anomalies and the complex nature of real-world datasets make anomaly detection a challenging unsupervised learning problem. In this paper, we propose a novel model-based anomaly detection method, that we call Out-of- Bag anomaly detection, which handles multi-dimensional datasets consisting of numerical and categorical features. The proposed method decomposes the unsupervised problem into the training of a set of ensemble models. Out-of-Bag estimates are leveraged to derive an effective measure for anomaly detection. We not only demonstrate the state-of-the-art performance of our method through comprehensive experiments on benchmark datasets, but also show our model can improve the accuracy and reliability of an ML system as data pre-processing step via a case study on home valuation.
A General Framework for Fairness in Multistakeholder Recommendations
Sep 04, 2020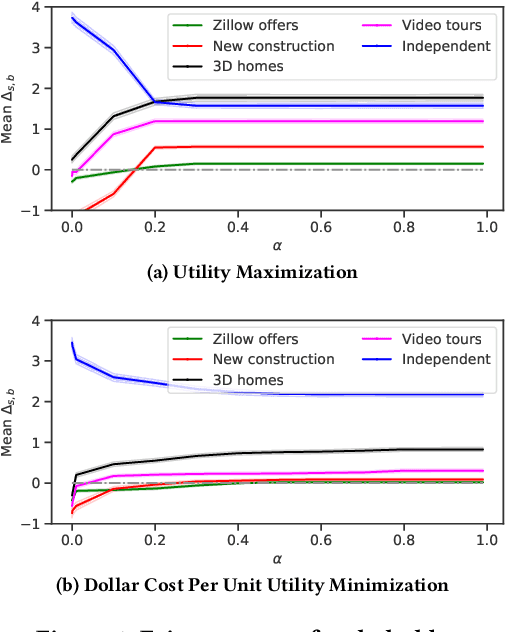
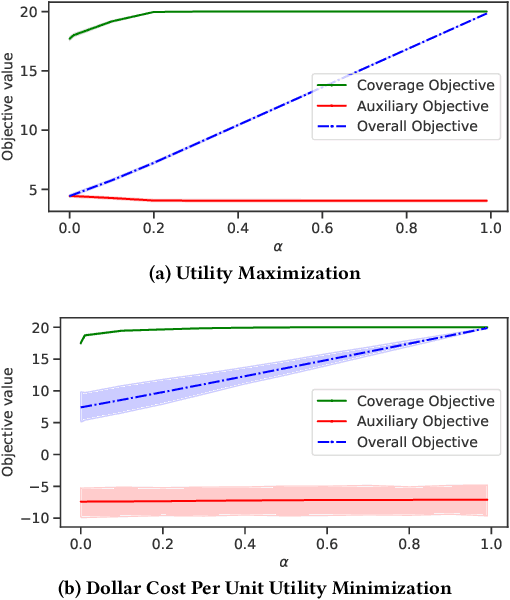
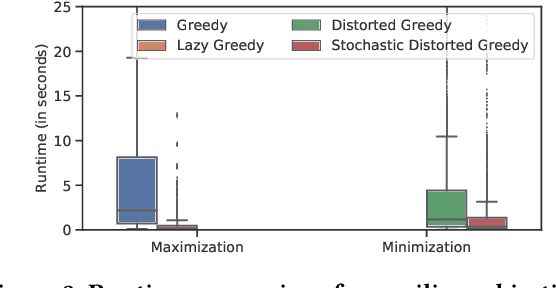
Contemporary recommender systems act as intermediaries on multi-sided platforms serving high utility recommendations from sellers to buyers. Such systems attempt to balance the objectives of multiple stakeholders including sellers, buyers, and the platform itself. The difficulty in providing recommendations that maximize the utility for a buyer, while simultaneously representing all the sellers on the platform has lead to many interesting research problems.Traditionally, they have been formulated as integer linear programs which compute recommendations for all the buyers together in an \emph{offline} fashion, by incorporating coverage constraints so that the individual sellers are proportionally represented across all the recommended items. Such approaches can lead to unforeseen biases wherein certain buyers consistently receive low utility recommendations in order to meet the global seller coverage constraints. To remedy this situation, we propose a general formulation that incorporates seller coverage objectives alongside individual buyer objectives in a real-time personalized recommender system. In addition, we leverage highly scalable submodular optimization algorithms to provide recommendations to each buyer with provable theoretical quality bounds. Furthermore, we empirically evaluate the efficacy of our approach using data from an online real-estate marketplace.