 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOut-Of-Bag Anomaly Detection
Sep 20, 2020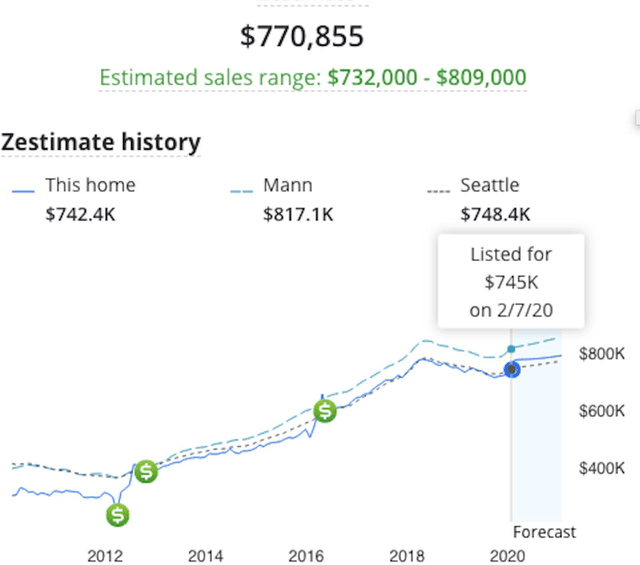

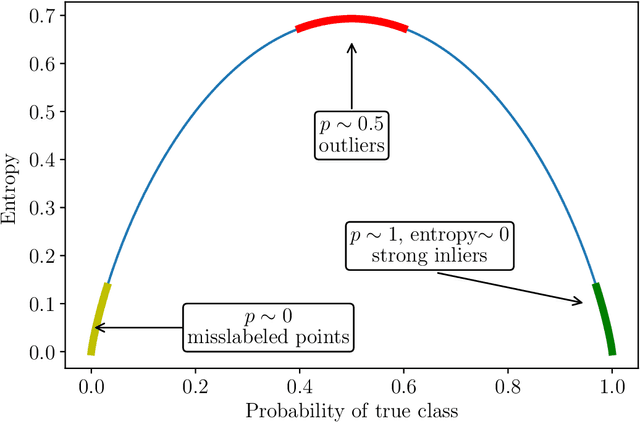
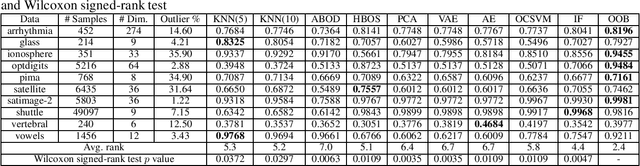
Data anomalies are ubiquitous in real world datasets, and can have an adverse impact on machine learning (ML) systems, such as automated home valuation. Detecting anomalies could make ML applications more responsible and trustworthy. However, the lack of labels for anomalies and the complex nature of real-world datasets make anomaly detection a challenging unsupervised learning problem. In this paper, we propose a novel model-based anomaly detection method, that we call Out-of- Bag anomaly detection, which handles multi-dimensional datasets consisting of numerical and categorical features. The proposed method decomposes the unsupervised problem into the training of a set of ensemble models. Out-of-Bag estimates are leveraged to derive an effective measure for anomaly detection. We not only demonstrate the state-of-the-art performance of our method through comprehensive experiments on benchmark datasets, but also show our model can improve the accuracy and reliability of an ML system as data pre-processing step via a case study on home valuation.