 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeApplicability and interpretation of the deterministic weighted cepstral distance
Mar 08, 2018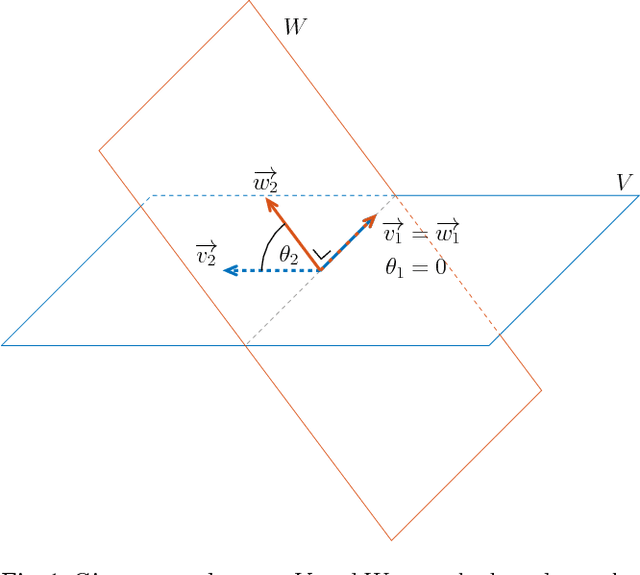


Quantifying similarity between data objects is an important part of modern data science. Deciding what similarity measure to use is very application dependent. In this paper, we combine insights from systems theory and machine learning, and investigate the weighted cepstral distance, which was previously defined for signals coming from ARMA models. We provide an extension of this distance to invertible deterministic linear time invariant single input single output models, and assess its applicability. We show that it can always be interpreted in terms of the poles and zeros of the underlying model, and that, in the case of stable, minimum-phase, or unstable, maximum-phase models, a geometrical interpretation in terms of subspace angles can be given. We then devise a method to assess stability and phase-type of the generating models, using only input/output signal information. In this way, we prove a connection between the extended weighted cepstral distance and a weighted cepstral model norm. In this way, we provide a purely data-driven way to assess different underlying dynamics of input/output signal pairs, without the need for any system identification step. This can be useful in machine learning tasks such as time series clustering. An iPython tutorial is published complementary to this paper, containing implementations of the various methods and algorithms presented here, as well as some numerical illustrations of the equivalences proven here.
A time series distance measure for efficient clustering of input output signals by their underlying dynamics
Mar 06, 2017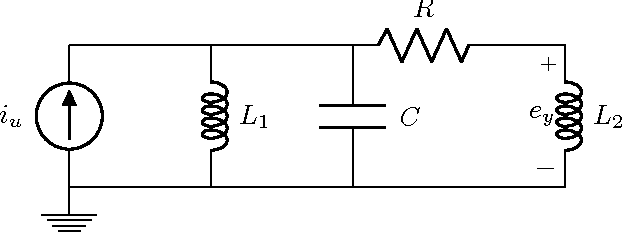
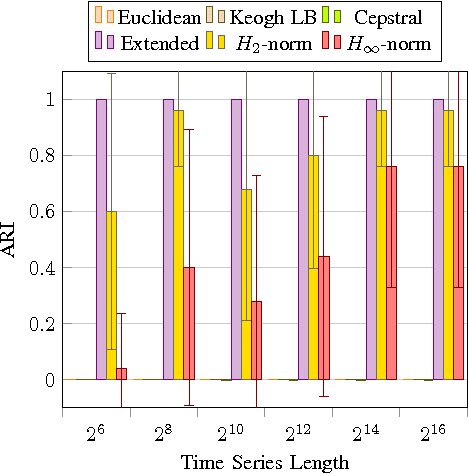
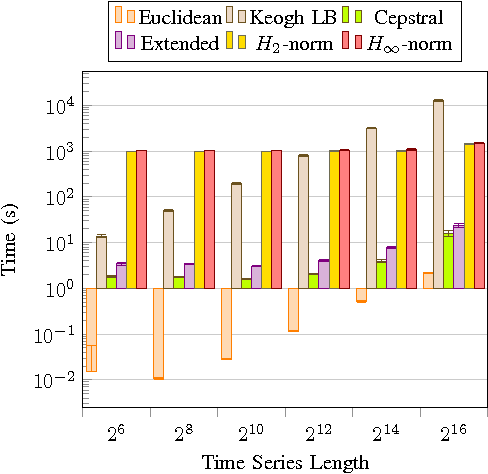
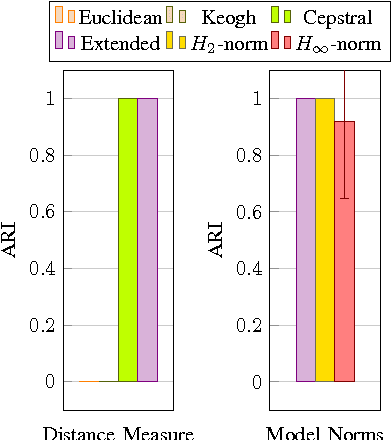
Starting from a dataset with input/output time series generated by multiple deterministic linear dynamical systems, this paper tackles the problem of automatically clustering these time series. We propose an extension to the so-called Martin cepstral distance, that allows to efficiently cluster these time series, and apply it to simulated electrical circuits data. Traditionally, two ways of handling the problem are used. The first class of methods employs a distance measure on time series (e.g. Euclidean, Dynamic Time Warping) and a clustering technique (e.g. k-means, k-medoids, hierarchical clustering) to find natural groups in the dataset. It is, however, often not clear whether these distance measures effectively take into account the specific temporal correlations in these time series. The second class of methods uses the input/output data to identify a dynamic system using an identification scheme, and then applies a model norm-based distance (e.g. H2, H-infinity) to find out which systems are similar. This, however, can be very time consuming for large amounts of long time series data. We show that the new distance measure presented in this paper performs as good as when every input/output pair is modelled explicitly, but remains computationally much less complex. The complexity of calculating this distance between two time series of length N is O(N logN).