 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCognitive Prompts Using Guilford's Structure of Intellect Model
Mar 27, 2025Large language models (LLMs) demonstrate strong language generation capabilities but often struggle with structured reasoning, leading to inconsistent or suboptimal problem-solving. To mitigate this limitation, Guilford's Structure of Intellect (SOI) model - a foundational framework from intelligence theory - is leveraged as the basis for cognitive prompt engineering. The SOI model categorizes cognitive operations such as pattern recognition, memory retrieval, and evaluation, offering a systematic approach to enhancing LLM reasoning and decision-making. This position paper presents a novel cognitive prompting approach for enforcing SOI-inspired reasoning for improving clarity, coherence, and adaptability in model responses.
Conceptual Metaphor Theory as a Prompting Paradigm for Large Language Models
Feb 04, 2025



We introduce Conceptual Metaphor Theory (CMT) as a framework for enhancing large language models (LLMs) through cognitive prompting in complex reasoning tasks. CMT leverages metaphorical mappings to structure abstract reasoning, improving models' ability to process and explain intricate concepts. By incorporating CMT-based prompts, we guide LLMs toward more structured and human-like reasoning patterns. To evaluate this approach, we compare four native models (Llama3.2, Phi3, Gemma2, and Mistral) against their CMT-augmented counterparts on benchmark tasks spanning domain-specific reasoning, creative insight, and metaphor interpretation. Responses were automatically evaluated using the Llama3.3 70B model. Experimental results indicate that CMT prompting significantly enhances reasoning accuracy, clarity, and metaphorical coherence, outperforming baseline models across all evaluated tasks.
Unlocking Structured Thinking in Language Models with Cognitive prompting
Oct 03, 2024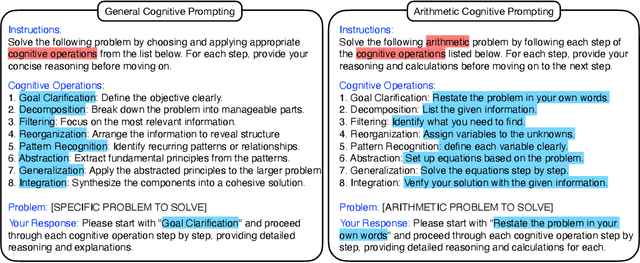



We propose cognitive prompting as a novel approach to guide problem-solving in large language models (LLMs) through structured, human-like cognitive operations such as goal clarification, decomposition, filtering, abstraction, and pattern recognition. By employing systematic, step-by-step reasoning, cognitive prompting enables LLMs to efficiently tackle complex, multi-step tasks. We evaluate the effectiveness of cognitive prompting on Meta's LLaMA models, comparing performance on arithmetic reasoning tasks using the GSM8K dataset and on commonsense reasoning benchmarks. Our analysis includes comparisons between models without cognitive prompting, models with a static sequence of cognitive operations, and models using reflective cognitive prompting, where the LLM dynamically self-selects the sequence of cognitive operations. The results show that cognitive prompting, particularly when dynamically adapted, significantly improves the performance of larger models, such as LLaMA3.1 70B, and enhances their ability to handle multi-step reasoning tasks. This approach also improves interpretability and flexibility, highlighting cognitive prompting as a promising strategy for general-purpose AI reasoning.
Towards Explainable Evolution Strategies with Large Language Models
Jul 11, 2024This paper introduces an approach that integrates self-adaptive Evolution Strategies (ES) with Large Language Models (LLMs) to enhance the explainability of complex optimization processes. By employing a self-adaptive ES equipped with a restart mechanism, we effectively navigate the challenging landscapes of benchmark functions, capturing detailed logs of the optimization journey, including fitness evolution, step-size adjustments, and restart events due to stagnation. An LLM is then utilized to process these logs, generating concise, user-friendly summaries that highlight key aspects such as convergence behavior, optimal fitness achievements, and encounters with local optima. Our case study on the Rastrigin function demonstrates how our approach makes the complexities of ES optimization transparent and accessible. Our findings highlight the potential of using LLMs to bridge the gap between advanced optimization algorithms and their interpretability.
Large Language Models for Tuning Evolution Strategies
May 16, 2024

Large Language Models (LLMs) exhibit world knowledge and inference capabilities, making them powerful tools for various applications. This paper proposes a feedback loop mechanism that leverages these capabilities to tune Evolution Strategies (ES) parameters effectively. The mechanism involves a structured process of providing programming instructions, executing the corresponding code, and conducting thorough analysis. This process is specifically designed for the optimization of ES parameters. The method operates through an iterative cycle, ensuring continuous refinement of the ES parameters. First, LLMs process the instructions to generate or modify the code. The code is then executed, and the results are meticulously logged. Subsequent analysis of these results provides insights that drive further improvements. An experiment on tuning the learning rates of ES using the LLaMA3 model demonstrate the feasibility of this approach. This research illustrates how LLMs can be harnessed to improve ES algorithms' performance and suggests broader applications for similar feedback loop mechanisms in various domains.
Evolutionary Multi-Objective Optimization of Large Language Model Prompts for Balancing Sentiments
Jan 18, 2024The advent of large language models (LLMs) such as ChatGPT has attracted considerable attention in various domains due to their remarkable performance and versatility. As the use of these models continues to grow, the importance of effective prompt engineering has come to the fore. Prompt optimization emerges as a crucial challenge, as it has a direct impact on model performance and the extraction of relevant information. Recently, evolutionary algorithms (EAs) have shown promise in addressing this issue, paving the way for novel optimization strategies. In this work, we propose a evolutionary multi-objective (EMO) approach specifically tailored for prompt optimization called EMO-Prompts, using sentiment analysis as a case study. We use sentiment analysis capabilities as our experimental targets. Our results demonstrate that EMO-Prompts effectively generates prompts capable of guiding the LLM to produce texts embodying two conflicting emotions simultaneously.
Comparing Heuristics, Constraint Optimization, and Reinforcement Learning for an Industrial 2D Packing Problem
Oct 27, 2021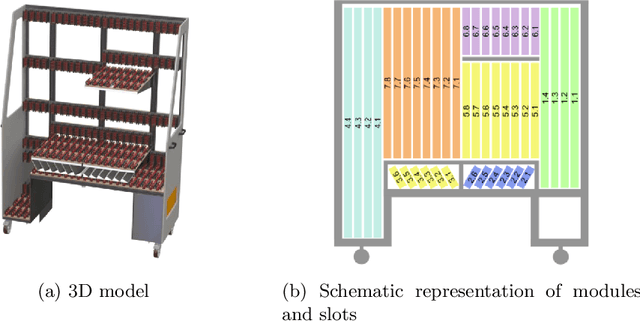
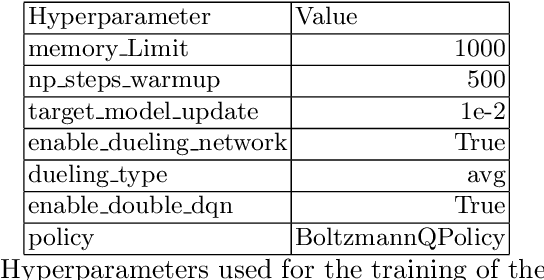
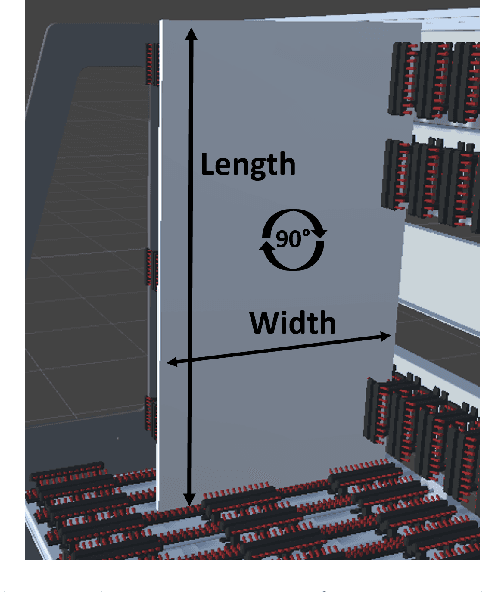
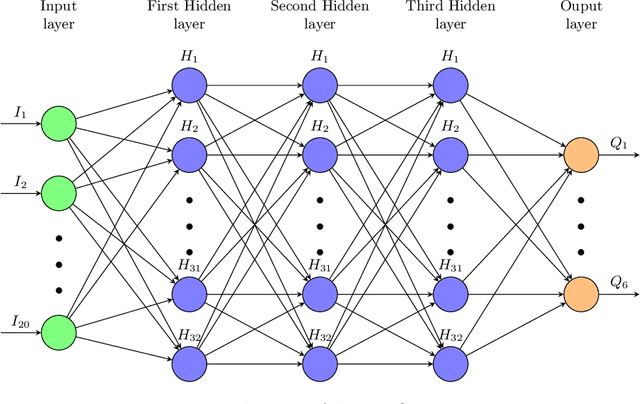
Cutting and Packing problems are occurring in different industries with a direct impact on the revenue of businesses. Generally, the goal in Cutting and Packing is to assign a set of smaller objects to a set of larger objects. To solve Cutting and Packing problems, practitioners can resort to heuristic and exact methodologies. Lately, machine learning is increasingly used for solving such problems. This paper considers a 2D packing problem from the furniture industry, where a set of wooden workpieces must be assigned to different modules of a trolley in the most space-saving way. We present an experimental setup to compare heuristics, constraint optimization, and deep reinforcement learning for the given problem. The used methodologies and their results get collated in terms of their solution quality and runtime. In the given use case a greedy heuristic produces optimal results and outperforms the other approaches in terms of runtime. Constraint optimization also produces optimal results but requires more time to perform. The deep reinforcement learning approach did not always produce optimal or even feasible solutions. While we assume this could be remedied with more training, considering the good results with the heuristic, deep reinforcement learning seems to be a bad fit for the given use case.
Earnings Prediction with Deep Leaning
Jun 03, 2020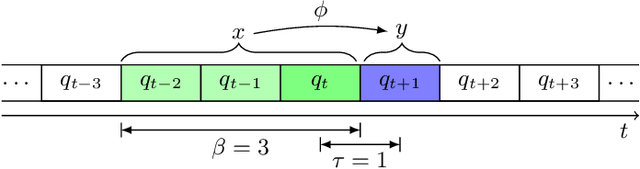


In the financial sector, a reliable forecast the future financial performance of a company is of great importance for investors' investment decisions. In this paper we compare long-term short-term memory (LSTM) networks to temporal convolution network (TCNs) in the prediction of future earnings per share (EPS). The experimental analysis is based on quarterly financial reporting data and daily stock market returns. For a broad sample of US firms, we find that both LSTMs outperform the naive persistent model with up to 30.0% more accurate predictions, while TCNs achieve and an improvement of 30.8%. Both types of networks are at least as accurate as analysts and exceed them by up to 12.2% (LSTM) and 13.2% (TCN).
Evolutionary Multi-Objective Design of SARS-CoV-2 Protease Inhibitor Candidates
May 18, 2020



Computational drug design based on artificial intelligence is an emerging research area. At the time of writing this paper, the world suffers from an outbreak of the coronavirus SARS-CoV-2. A promising way to stop the virus replication is via protease inhibition. We propose an evolutionary multi-objective algorithm (EMOA) to design potential protease inhibitors for SARS-CoV-2's main protease. Based on the SELFIES representation the EMOA maximizes the binding of candidate ligands to the protein using the docking tool QuickVina 2, while at the same time taking into account further objectives like drug-likeliness or the fulfillment of filter constraints. The experimental part analyzes the evolutionary process and discusses the inhibitor candidates.
Learned Weight Sharing for Deep Multi-Task Learning by Natural Evolution Strategy and Stochastic Gradient Descent
Mar 23, 2020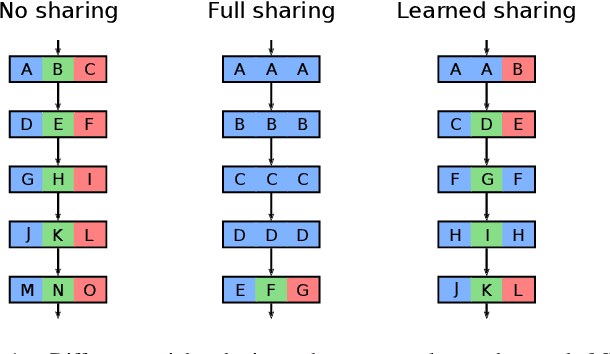


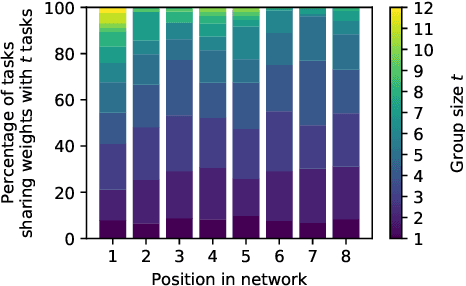
In deep multi-task learning, weights of task-specific networks are shared between tasks to improve performance on each single one. Since the question, which weights to share between layers, is difficult to answer, human-designed architectures often share everything but a last task-specific layer. In many cases, this simplistic approach severely limits performance. Instead, we propose an algorithm to learn the assignment between a shared set of weights and task-specific layers. To optimize the non-differentiable assignment and at the same time train the differentiable weights, learning takes place via a combination of natural evolution strategy and stochastic gradient descent. The end result are task-specific networks that share weights but allow independent inference. They achieve lower test errors than baselines and methods from literature on three multi-task learning datasets.