 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImage-to-Graph Transformers for Chemical Structure Recognition
Feb 19, 2022
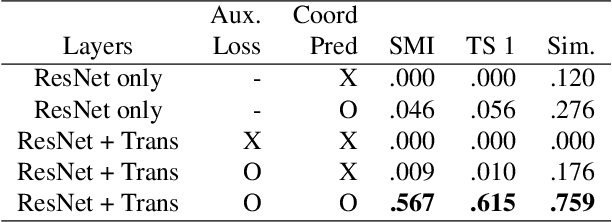

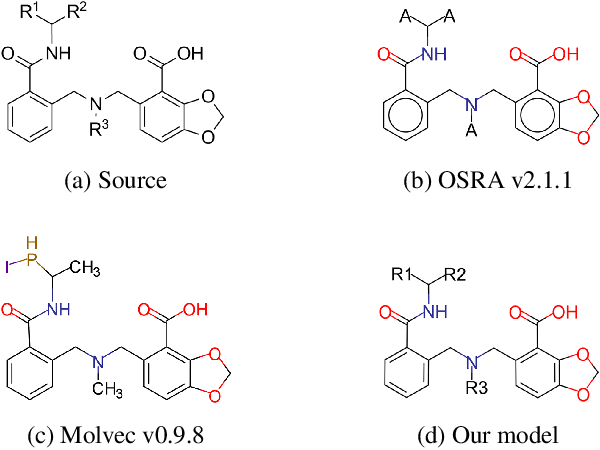
For several decades, chemical knowledge has been published in written text, and there have been many attempts to make it accessible, for example, by transforming such natural language text to a structured format. Although the discovered chemical itself commonly represented in an image is the most important part, the correct recognition of the molecular structure from the image in literature still remains a hard problem since they are often abbreviated to reduce the complexity and drawn in many different styles. In this paper, we present a deep learning model to extract molecular structures from images. The proposed model is designed to transform the molecular image directly into the corresponding graph, which makes it capable of handling non-atomic symbols for abbreviations. Also, by end-to-end learning approach it can fully utilize many open image-molecule pair data from various sources, and hence it is more robust to image style variation than other tools. The experimental results show that the proposed model outperforms the existing models with 17.1 % and 12.8 % relative improvement for well-known benchmark datasets and large molecular images that we collected from literature, respectively.