 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale, Language-agnostic Discourse Classification of Tweets During COVID-19
Aug 02, 2020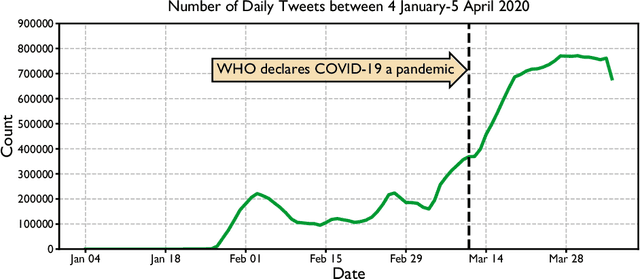
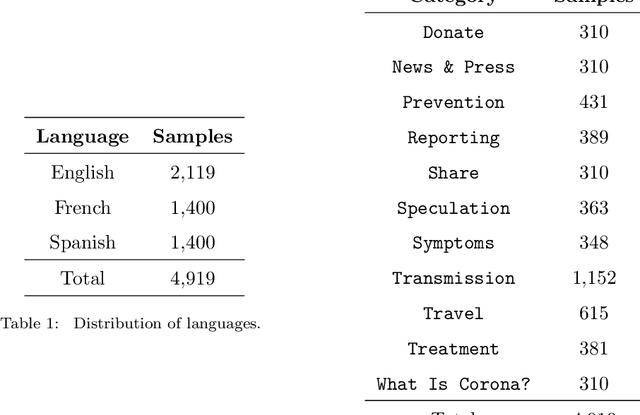
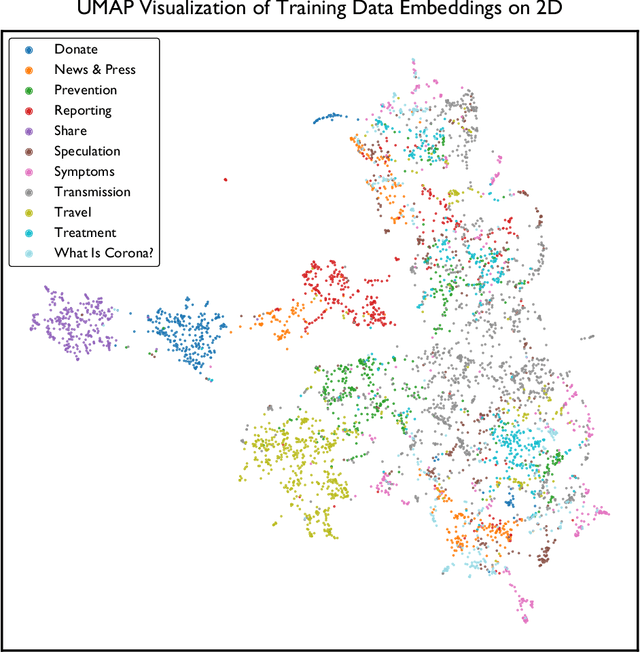

Quantifying the characteristics of public attention is an essential prerequisite for appropriate crisis management during severe events such as pandemics. For this purpose, we propose language-agnostic tweet representations to perform large-scale Twitter discourse classification with machine learning. Our analysis on more than 26 million COVID-19 tweets show that large-scale surveillance of public discourse is feasible with computationally lightweight classifiers by out-of-the-box utilization of these representations.
Causal Modeling of Twitter Activity During COVID-19
Jun 06, 2020Understanding the characteristics of public attention and perception is an essential prerequisite for appropriate crisis management during adverse health events. This is even more crucial during a pandemic such as COVID-19, as primary responsibility of risk management is not centralized to a single institution, but distributed across society. While numerous studies utilize Twitter data in descriptive or predictive context during COVID-19 pandemic, causal modeling of public attention has not been investigated. In this study, we propose a causal inference approach to discover and quantify causal relationships between pandemic characteristics (e.g. number of infections and deaths) and Twitter activity as well as public sentiment. Our results show that the proposed method can successfully capture the epidemiological domain knowledge and identify variables that affect public attention and perception. We believe our work contributes to the field of infodemiology by distinguishing events that correlate with public attention from events that cause public attention.
Cyberbullying Detection with Fairness Constraints
May 09, 2020

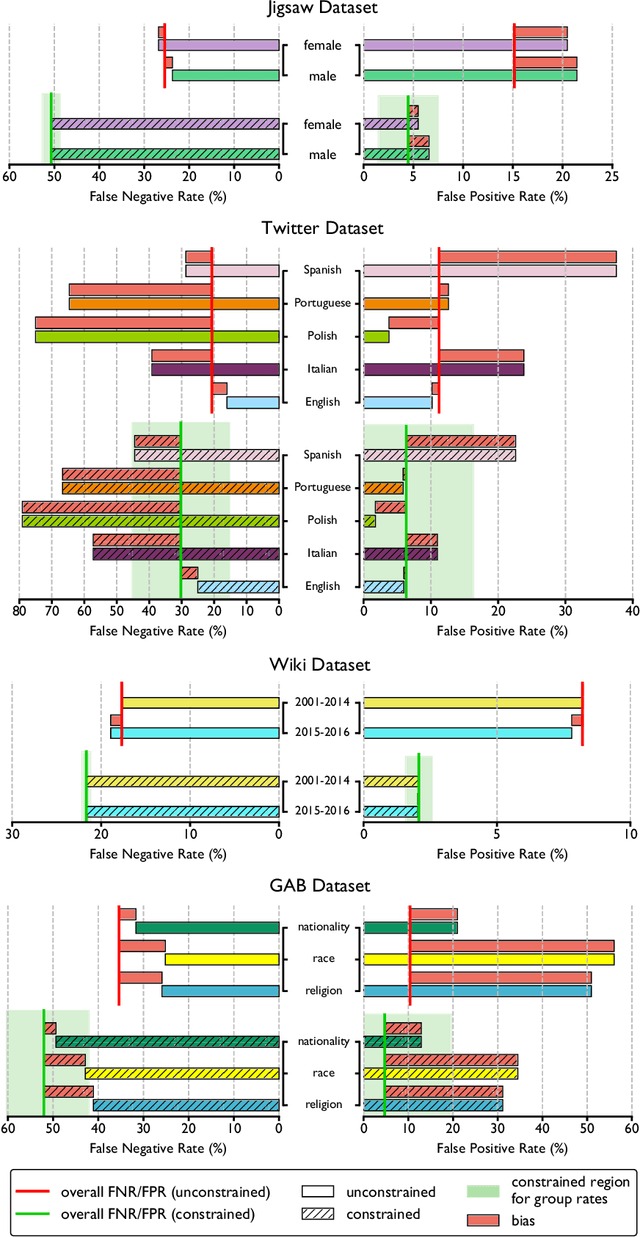

Cyberbullying is a widespread adverse phenomenon among online social interactions in today's digital society. While numerous computational studies focus on enhancing the cyberbullying detection performance of machine learning algorithms, proposed models tend to carry and reinforce unintended social biases. In this study, we try to answer the research question of "Can we mitigate the unintended bias of cyberbullying detection models by guiding the model training with fairness constraints?". For this purpose, we propose a model training scheme that can employ fairness constraints and validate our approach with different datasets. We demonstrate that various types of unintended biases can be successfully mitigated without impairing the model quality. We believe our work contributes to the pursuit of unbiased, transparent, and ethical machine learning solutions for cyber-social health.
HARK Side of Deep Learning -- From Grad Student Descent to Automated Machine Learning
Apr 16, 2019Recent advancements in machine learning research, i.e., deep learning, introduced methods that excel conventional algorithms as well as humans in several complex tasks, ranging from detection of objects in images and speech recognition to playing difficult strategic games. However, the current methodology of machine learning research and consequently, implementations of the real-world applications of such algorithms, seems to have a recurring HARKing (Hypothesizing After the Results are Known) issue. In this work, we elaborate on the algorithmic, economic and social reasons and consequences of this phenomenon. We present examples from current common practices of conducting machine learning research (e.g. avoidance of reporting negative results) and failure of generalization ability of the proposed algorithms and datasets in actual real-life usage. Furthermore, a potential future trajectory of machine learning research and development from the perspective of accountable, unbiased, ethical and privacy-aware algorithmic decision making is discussed. We would like to emphasize that with this discussion we neither claim to provide an exhaustive argumentation nor blame any specific institution or individual on the raised issues. This is simply a discussion put forth by us, insiders of the machine learning field, reflecting on us.
Improving Prostate Cancer Detection with Breast Histopathology Images
Mar 14, 2019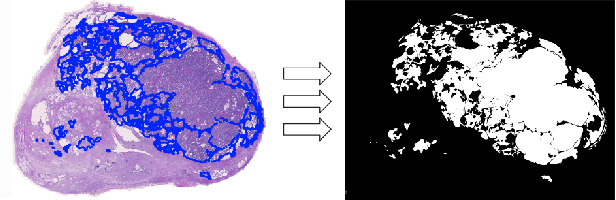
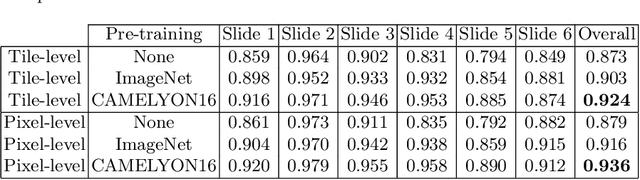
Deep neural networks have introduced significant advancements in the field of machine learning-based analysis of digital pathology images including prostate tissue images. With the help of transfer learning, classification and segmentation performance of neural network models have been further increased. However, due to the absence of large, extensively annotated, publicly available prostate histopathology datasets, several previous studies employ datasets from well-studied computer vision tasks such as ImageNet dataset. In this work, we propose a transfer learning scheme from breast histopathology images to improve prostate cancer detection performance. We validate our approach on annotated prostate whole slide images by using a publicly available breast histopathology dataset as pre-training. We show that the proposed cross-cancer approach outperforms transfer learning from ImageNet dataset.
Deep Representation Learning for Clustering of Health Tweets
Dec 25, 2018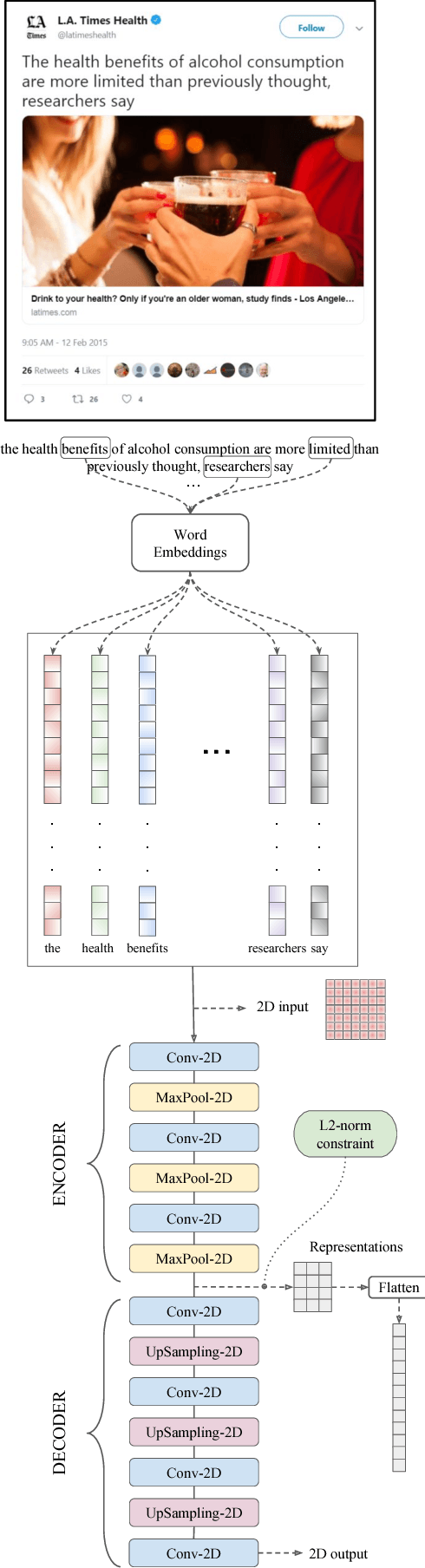
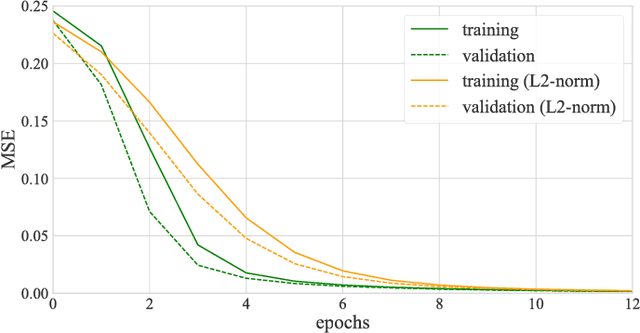


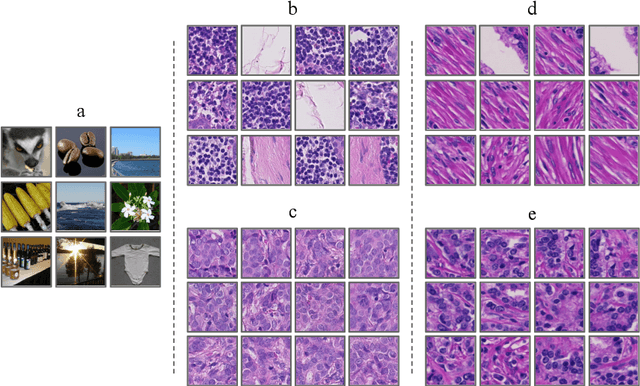
Twitter has been a prominent social media platform for mining population-level health data and accurate clustering of health-related tweets into topics is important for extracting relevant health insights. In this work, we propose deep convolutional autoencoders for learning compact representations of health-related tweets, further to be employed in clustering. We compare our method to several conventional tweet representation methods including bag-of-words, term frequency-inverse document frequency, Latent Dirichlet Allocation and Non-negative Matrix Factorization with 3 different clustering algorithms. Our results show that the clustering performance using proposed representation learning scheme significantly outperforms that of conventional methods for all experiments of different number of clusters. In addition, we propose a constraint on the learned representations during the neural network training in order to further enhance the clustering performance. All in all, this study introduces utilization of deep neural network-based architectures, i.e., deep convolutional autoencoders, for learning informative representations of health-related tweets.
Predicting the Flu from Instagram
Nov 27, 2018

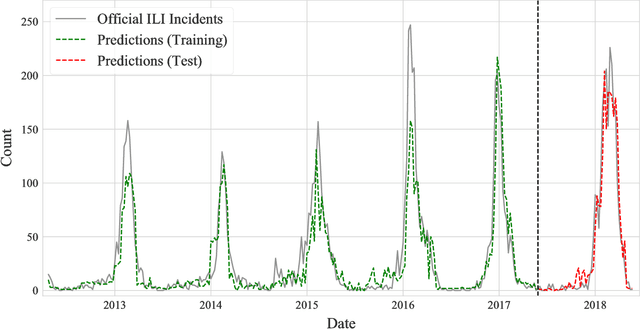
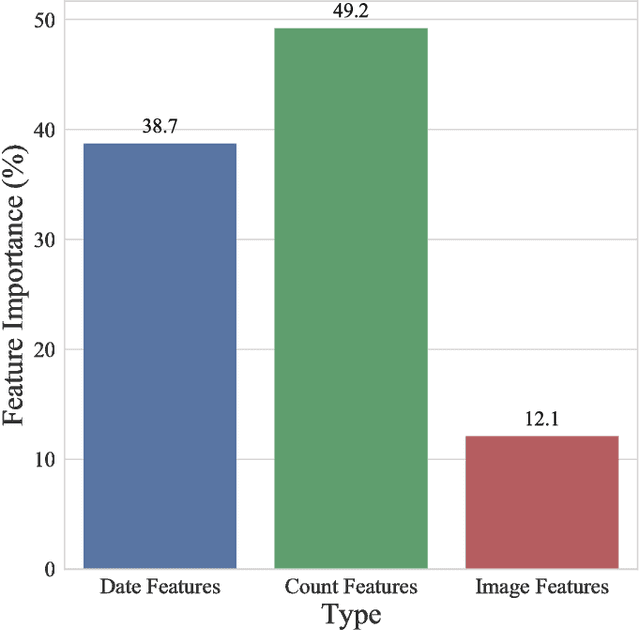
Conventional surveillance systems for monitoring infectious diseases, such as influenza, face challenges due to shortage of skilled healthcare professionals, remoteness of communities and absence of communication infrastructures. Internet-based approaches for surveillance are appealing logistically as well as economically. Search engine queries and Twitter have been the primarily used data sources in such approaches. The aim of this study is to assess the predictive power of an alternative data source, Instagram. By using 317 weeks of publicly available data from Instagram, we trained several machine learning algorithms to both nowcast and forecast the number of official influenza-like illness incidents in Finland where population-wide official statistics about the weekly incidents are available. In addition to date and hashtag count features of online posts, we were able to utilize also the visual content of the posted images with the help of deep convolutional neural networks. Our best nowcasting model reached a mean absolute error of 11.33 incidents per week and a correlation coefficient of 0.963 on the test data. Forecasting models for predicting 1 week and 2 weeks ahead showed statistical significance as well by reaching correlation coefficients of 0.903 and 0.862, respectively. This study demonstrates how social media and in particular, digital photographs shared in them, can be a valuable source of information for the field of infodemiology.