 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePeerRank: Autonomous LLM Evaluation Through Web-Grounded, Bias-Controlled Peer Review
Feb 01, 2026Evaluating large language models typically relies on human-authored benchmarks, reference answers, and human or single-model judgments, approaches that scale poorly, become quickly outdated, and mismatch open-world deployments that depend on web retrieval and synthesis. We introduce PeerRank, a fully autonomous end-to-end evaluation framework in which models generate evaluation tasks, answer them with category-scoped live web grounding, judge peer responses and aggregate dense peer assessments into relative performance estimates, without human supervision or gold references. PeerRank treats evaluation as a multi-agent process where each model participates symmetrically as task designer, respondent, and evaluator, while removing biased judgments. In a large-scale study over 12 commercially available models and 420 autonomously generated questions, PeerRank produces stable, discriminative rankings and reveals measurable identity and presentation biases. Rankings are robust, and mean peer scores agree with Elo. We further validate PeerRank on TruthfulQA and GSM8K, where peer scores correlate with objective accuracy. Together, these results suggest that bias-aware peer evaluation with selective web-grounded answering can scale open-world LLM assessment beyond static and human curated benchmarks.
Evolving Assembly Code in an Adversarial Environment
Mar 28, 2024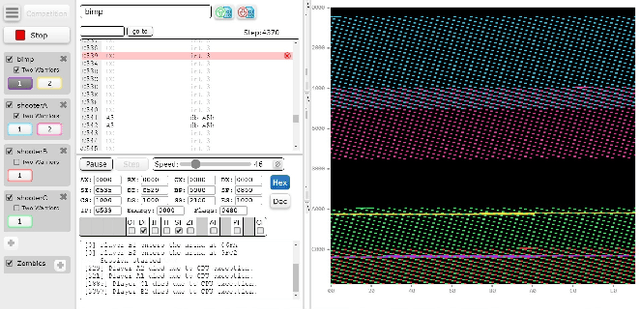
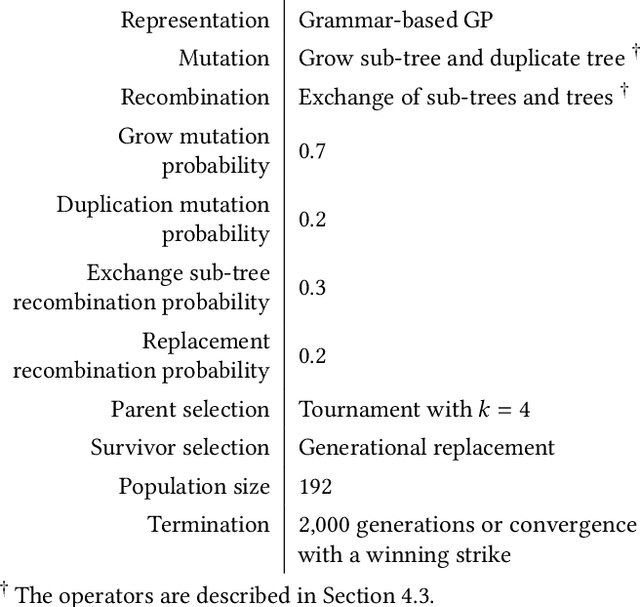
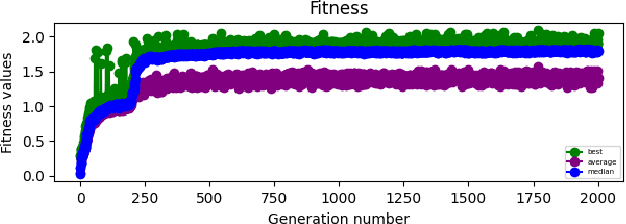
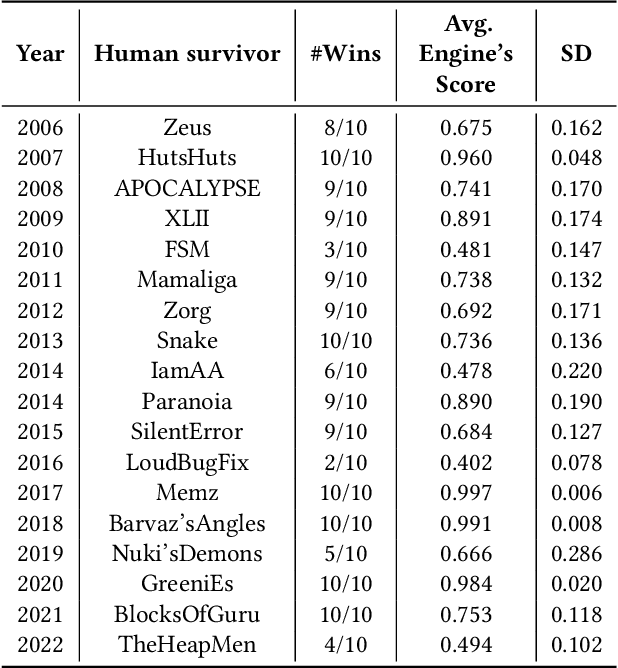
In this work, we evolve assembly code for the CodeGuru competition. The competition's goal is to create a survivor -- an assembly program that runs the longest in shared memory, by resisting attacks from adversary survivors and finding their weaknesses. For evolving top-notch solvers, we specify a Backus Normal Form (BNF) for the assembly language and synthesize the code from scratch using Genetic Programming (GP). We evaluate the survivors by running CodeGuru games against human-written winning survivors. Our evolved programs found weaknesses in the programs they were trained against and utilized them. In addition, we compare our approach with a Large-Language Model, demonstrating that the latter cannot generate a survivor that can win at any competition. This work has important applications for cyber-security, as we utilize evolution to detect weaknesses in survivors. The assembly BNF is domain-independent; thus, by modifying the fitness function, it can detect code weaknesses and help fix them. Finally, the CodeGuru competition offers a novel platform for analyzing GP and code evolution in adversarial environments. To support further research in this direction, we provide a thorough qualitative analysis of the evolved survivors and the weaknesses found.