 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNIMBA: Towards Robust and Principled Processing of Point Clouds With SSMs
Oct 31, 2024

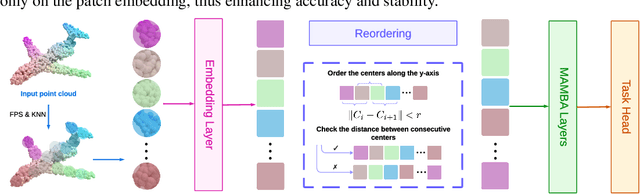
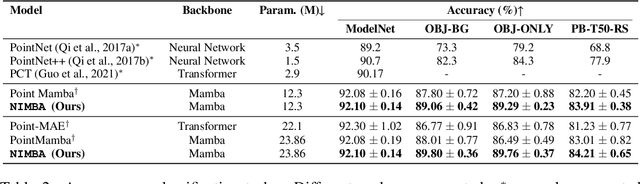
Transformers have become dominant in large-scale deep learning tasks across various domains, including text, 2D and 3D vision. However, the quadratic complexity of their attention mechanism limits their efficiency as the sequence length increases, particularly in high-resolution 3D data such as point clouds. Recently, state space models (SSMs) like Mamba have emerged as promising alternatives, offering linear complexity, scalability, and high performance in long-sequence tasks. The key challenge in the application of SSMs in this domain lies in reconciling the non-sequential structure of point clouds with the inherently directional (or bi-directional) order-dependent processing of recurrent models like Mamba. To achieve this, previous research proposed reorganizing point clouds along multiple directions or predetermined paths in 3D space, concatenating the results to produce a single 1D sequence capturing different views. In our work, we introduce a method to convert point clouds into 1D sequences that maintain 3D spatial structure with no need for data replication, allowing Mamba sequential processing to be applied effectively in an almost permutation-invariant manner. In contrast to other works, we found that our method does not require positional embeddings and allows for shorter sequence lengths while still achieving state-of-the-art results in ModelNet40 and ScanObjectNN datasets and surpassing Transformer-based models in both accuracy and efficiency.