 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Opinion Aggregation -- A Statistical Perspective
Aug 20, 2023


Complex decision-making systems rarely have direct access to the current state of the world and they instead rely on opinions to form an understanding of what the ground truth could be. Even in problems where experts provide opinions without any intention to manipulate the decision maker, it is challenging to decide which expert's opinion is more reliable -- a challenge that is further amplified when decision-maker has limited, delayed, or no access to the ground truth after the fact. This paper explores a statistical approach to infer the competence of each expert based on their opinions without any need for the ground truth. Echoing the logic behind what is commonly referred to as \textit{the wisdom of crowds}, we propose measuring the competence of each expert by their likeliness to agree with their peers. We further show that the more reliable an expert is the more likely it is that they agree with their peers. We leverage this fact to propose a completely unsupervised version of the na\"{i}ve Bayes classifier and show that the proposed technique is asymptotically optimal for a large class of problems. In addition to aggregating a large block of opinions, we further apply our technique for online opinion aggregation and for decision-making based on a limited the number of opinions.
Blind Exploration and Exploitation of Stochastic Experts
Apr 02, 2021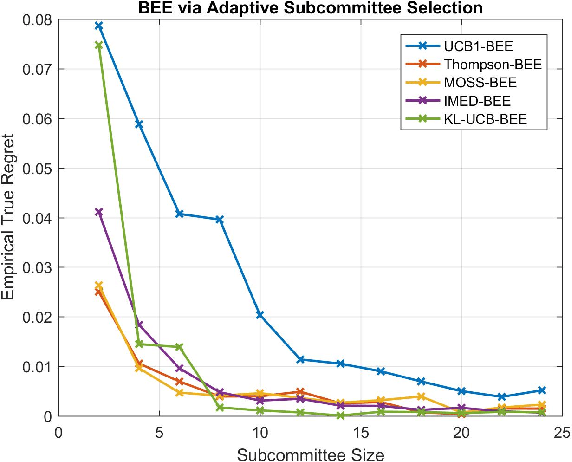

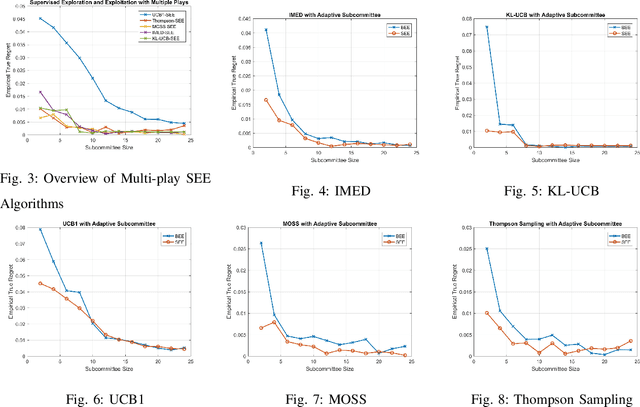
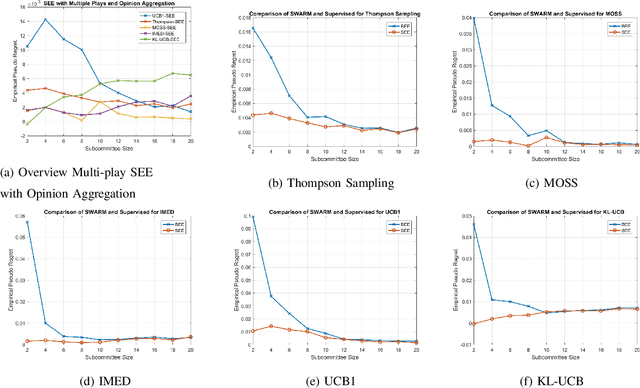
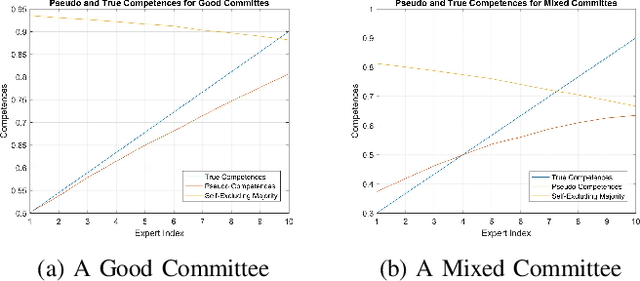
We present blind exploration and exploitation (BEE) algorithms for identifying the most reliable stochastic expert based on formulations that employ posterior sampling, upper-confidence bounds, empirical Kullback-Leibler divergence, and minmax methods for the stochastic multi-armed bandit problem. Joint sampling and consultation of experts whose opinions depend on the hidden and random state of the world becomes challenging in the unsupervised, or blind, framework as feedback from the true state is not available. We propose an empirically realizable measure of expert competence that can be inferred instantaneously using only the opinions of other experts. This measure preserves the ordering of true competences and thus enables joint sampling and consultation of stochastic experts based on their opinions on dynamically changing tasks. Statistics derived from the proposed measure is instantaneously available allowing both blind exploration-exploitation and unsupervised opinion aggregation. We discuss how the lack of supervision affects the asymptotic regret of BEE architectures that rely on UCB1, KL-UCB, MOSS, IMED, and Thompson sampling. We demonstrate the performance of different BEE algorithms empirically and compare them to their standard, or supervised, counterparts.