 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Interpretable Graph-based Mapping of Trustworthy Machine Learning Research
May 13, 2021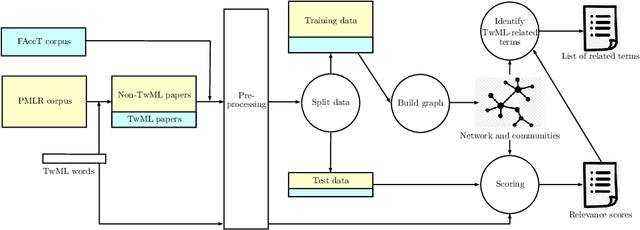
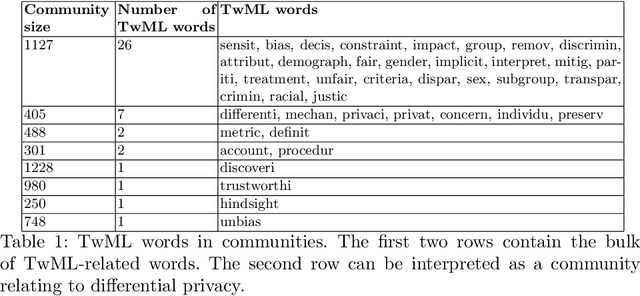
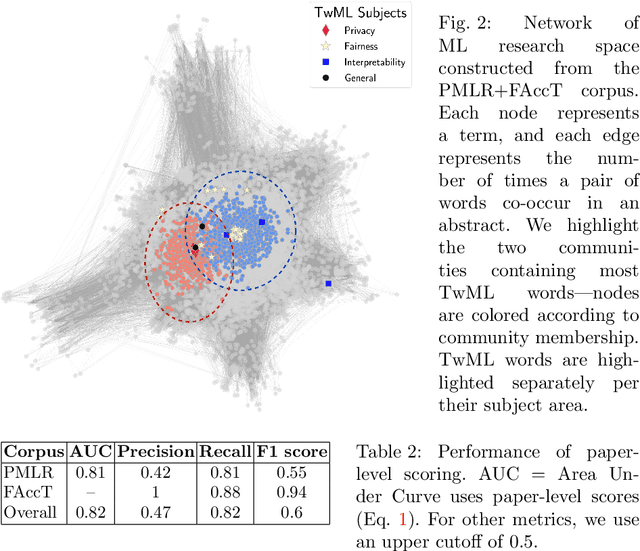

There is an increasing interest in ensuring machine learning (ML) frameworks behave in a socially responsible manner and are deemed trustworthy. Although considerable progress has been made in the field of Trustworthy ML (TwML) in the recent past, much of the current characterization of this progress is qualitative. Consequently, decisions about how to address issues of trustworthiness and future research goals are often left to the interested researcher. In this paper, we present the first quantitative approach to characterize the comprehension of TwML research. We build a co-occurrence network of words using a web-scraped corpus of more than 7,000 peer-reviewed recent ML papers -- consisting of papers both related and unrelated to TwML. We use community detection to obtain semantic clusters of words in this network that can infer relative positions of TwML topics. We propose an innovative fingerprinting algorithm to obtain probabilistic similarity scores for individual words, then combine them to give a paper-level relevance score. The outcomes of our analysis inform a number of interesting insights on advancing the field of TwML research.