 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA proposition of a robust system for historical document images indexation
Aug 28, 2013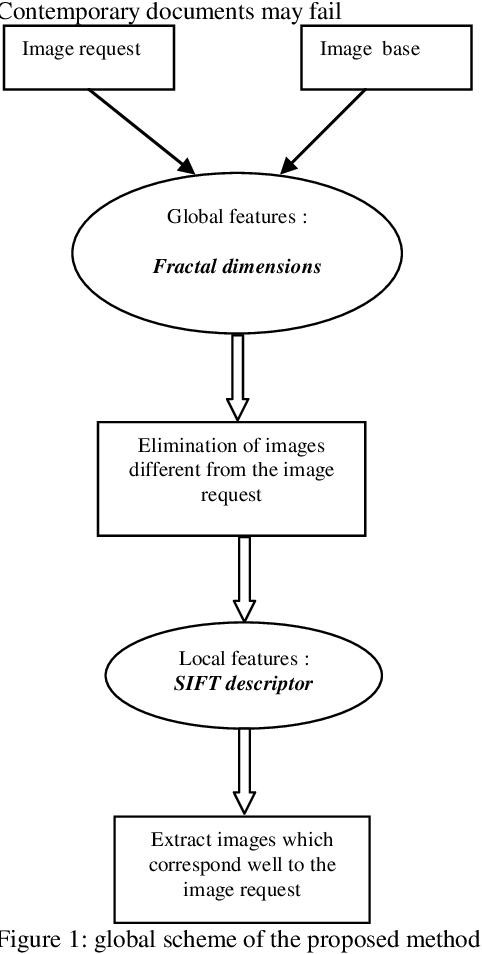



Characterizing noisy or ancient documents is a challenging problem up to now. Many techniques have been done in order to effectuate feature extraction and image indexation for such documents. Global approaches are in general less robust and exact than local approaches. That's why, we propose in this paper, a hybrid system based on global approach(fractal dimension), and a local one based on SIFT descriptor. The Scale Invariant Feature Transform seems to do well with our application since it's rotation invariant and relatively robust to changing illumination.In the first step the calculation of fractal dimension is applied to images in order to eliminate images which have distant features than image request characteristics. Next, the SIFT is applied to show which images match well the request. However the average matching time using the hybrid approach is better than "fractal dimension" and "SIFT descriptor" if they are used alone.
* 7 pages
Categorizing ancient documents
Aug 28, 2013
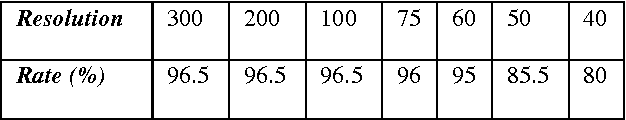

The analysis of historical documents is still a topical issue given the importance of information that can be extracted and also the importance given by the institutions to preserve their heritage. The main idea in order to characterize the content of the images of ancient documents after attempting to clean the image is segmented blocks texts from the same image and tries to find similar blocks in either the same image or the entire image database. Most approaches of offline handwriting recognition proceed by segmenting words into smaller pieces (usually characters) which are recognized separately. Recognition of a word then requires the recognition of all characters (OCR) that compose it. Our work focuses mainly on the characterization of classes in images of old documents. We use Som toolbox for finding classes in documents. We applied also fractal dimensions and points of interest to categorize and match ancient documents.
* 10 pages
Text recognition in both ancient and cartographic documents
Aug 28, 2013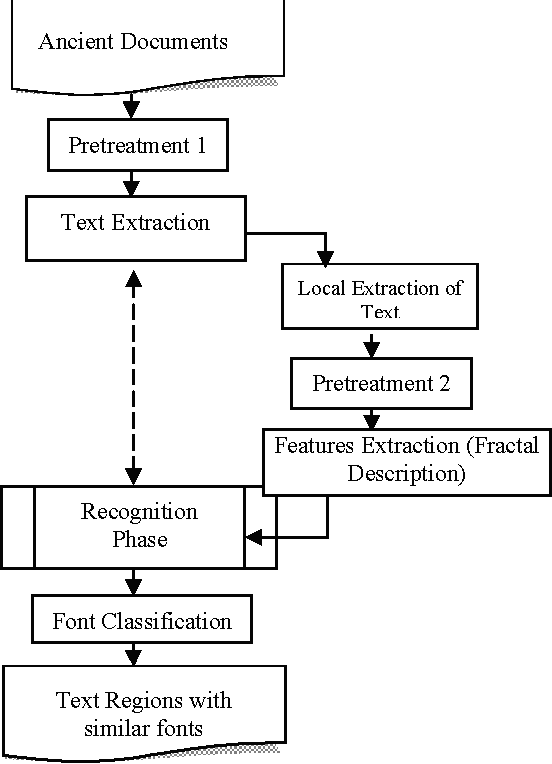



This paper deals with the recognition and matching of text in both cartographic maps and ancient documents. The purpose of this work is to find similar text regions based on statistical and global features. A phase of normalization is done first, in object to well categorize the same quantity of information. A phase of wordspotting is done next by combining local and global features. We make different experiments by combining the different techniques of extracting features in order to obtain better results in recognition phase. We applied fontspotting on both ancient documents and cartographic ones. We also applied the wordspotting in which we adopted a new technique which tries to compare the images of character and not the entire images words. We present the precision and recall values obtained with three methods for the new method of wordspotting applied on characters only.