 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeText recognition in both ancient and cartographic documents
Paper and Code
Aug 28, 2013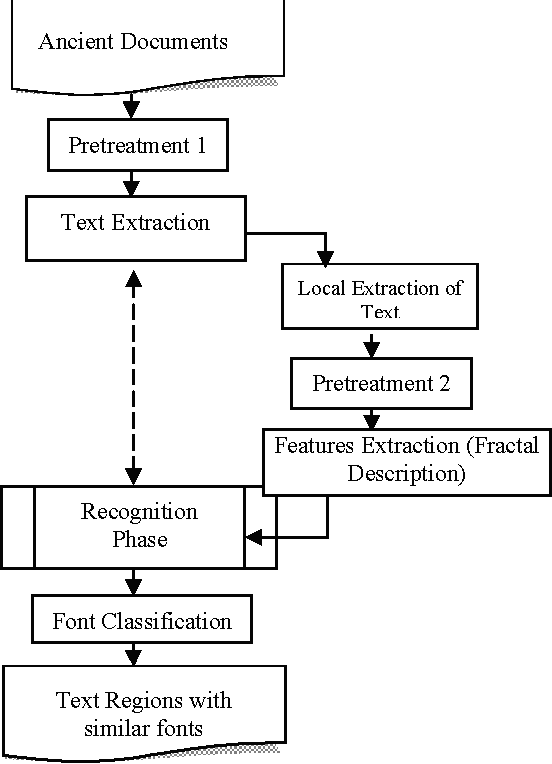



This paper deals with the recognition and matching of text in both cartographic maps and ancient documents. The purpose of this work is to find similar text regions based on statistical and global features. A phase of normalization is done first, in object to well categorize the same quantity of information. A phase of wordspotting is done next by combining local and global features. We make different experiments by combining the different techniques of extracting features in order to obtain better results in recognition phase. We applied fontspotting on both ancient documents and cartographic ones. We also applied the wordspotting in which we adopted a new technique which tries to compare the images of character and not the entire images words. We present the precision and recall values obtained with three methods for the new method of wordspotting applied on characters only.