 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Single-Image Facial Demorphing using Multimodal Large Language Models
May 25, 2026Face recognition systems are increasingly vulnerable to morphing attacks, where a composite image is crafted to match multiple identities, enabling unauthorized access and identity fraud. Existing detection methods identify morphed images but cannot recover constituent images or identities, limiting their forensic utility. This paper presents a novel reference-free facial demorphing framework that leverages Multimodal Large Language Models (MLLMs) to guide a coupled diffusion-based reconstruction process. Our key innovation lies in extracting semantic embeddings from intermediate MLLM layers to condition the demorphing, providing high-level reasoning about facial attributes and identity cues that complement low-level pixel information. We formulate demorphing as a coupled conditional generation problem, where both constituent faces are synthesized jointly through a denoising diffusion model operating directly in the RGB domain, ensuring inter-identity consistency while preserving fine-grained perceptual details. Unlike prior approaches that rely on compressed latent representations or assume identity overlap between training and testing sets, our method bypasses lossy text generation-reencoding cycles by directly utilizing MLLM hidden states as conditioning signals, enabling the denoising network to attend to subtle visual cues such as hair, background, and facial textures. Ablation studies further reveal that middle MLLM layers encode more identity-discriminative representations, RGB-domain demorphing outperforms latent-space approaches by 30--40\% at strict operating points, and full MLLM embeddings provide substantial advantages over raw ViT features through enhanced semantic structuring from multimodal pretraining.
S2H-DPO: Hardness-Aware Preference Optimization for Vision-Language Models
Apr 20, 2026Vision-Language Models (VLMs) have demonstrated remarkable progress in single-image understanding, yet effective reasoning across multiple images remains challenging. We identify a critical capability gap in existing multi-image alignment approaches: current methods focus primarily on localized reasoning with pre-specified image indices (``Look at Image 3 and...''), bypassing the essential skills of global visual search and autonomous cross-image comparison. To address this limitation, we introduce a Simple-to-Hard (S2H) learning framework that systematically constructs multi-image preference data across three hierarchical reasoning levels requiring an increasing level of capabilities: (1) single-image localized reasoning, (2) multi-image localized comparison, and (3) global visual search. Unlike prior work that relies on model-specific attributes, such as hallucinations or attention heuristics, to generate preference pairs, our approach leverages prompt-driven complexity to create chosen/rejected pairs that are applicable across different models. Through extensive evaluations on LLaVA and Qwen-VL models, we show that our diverse multi-image reasoning data significantly enhances multi-image reasoning performance, yielding significant improvements over baseline methods across benchmarks. Importantly, our approach maintains strong single-image reasoning performance while simultaneously strengthening multi-image understanding capabilities, thus advancing the state of the art for holistic visual preference alignment.
Benchmarking Foundation Models for Zero-Shot Biometric Tasks
May 30, 2025The advent of foundation models, particularly Vision-Language Models (VLMs) and Multi-modal Large Language Models (MLLMs), has redefined the frontiers of artificial intelligence, enabling remarkable generalization across diverse tasks with minimal or no supervision. Yet, their potential in biometric recognition and analysis remains relatively underexplored. In this work, we introduce a comprehensive benchmark that evaluates the zero-shot and few-shot performance of state-of-the-art publicly available VLMs and MLLMs across six biometric tasks spanning the face and iris modalities: face verification, soft biometric attribute prediction (gender and race), iris recognition, presentation attack detection (PAD), and face manipulation detection (morphs and deepfakes). A total of 41 VLMs were used in this evaluation. Experiments show that embeddings from these foundation models can be used for diverse biometric tasks with varying degrees of success. For example, in the case of face verification, a True Match Rate (TMR) of 96.77 percent was obtained at a False Match Rate (FMR) of 1 percent on the Labeled Face in the Wild (LFW) dataset, without any fine-tuning. In the case of iris recognition, the TMR at 1 percent FMR on the IITD-R-Full dataset was 97.55 percent without any fine-tuning. Further, we show that applying a simple classifier head to these embeddings can help perform DeepFake detection for faces, Presentation Attack Detection (PAD) for irides, and extract soft biometric attributes like gender and ethnicity from faces with reasonably high accuracy. This work reiterates the potential of pretrained models in achieving the long-term vision of Artificial General Intelligence.
diffDemorph: Extending Reference-Free Demorphing to Unseen Faces
May 20, 2025A face morph is created by combining two (or more) face images corresponding to two (or more) identities to produce a composite that successfully matches the constituent identities. Reference-free (RF) demorphing reverses this process using only the morph image, without the need for additional reference images. Previous RF demorphing methods were overly constrained, as they rely on assumptions about the distributions of training and testing morphs such as the morphing technique used, face style, and images used to create the morph. In this paper, we introduce a novel diffusion-based approach that effectively disentangles component images from a composite morph image with high visual fidelity. Our method is the first to generalize across morph techniques and face styles, beating the current state of the art by $\geq 59.46\%$ under a common training protocol across all datasets tested. We train our method on morphs created using synthetically generated face images and test on real morphs, thereby enhancing the practicality of the technique. Experiments on six datasets and two face matchers establish the utility and efficacy of our method.
Metric for Evaluating Performance of Reference-Free Demorphing Methods
Jan 21, 2025A facial morph is an image created by combining two (or more) face images pertaining to two (or more) distinct identities. Reference-free face demorphing inverts the process and tries to recover the face images constituting a facial morph without using any other information. However, there is no consensus on the evaluation metrics to be used to evaluate and compare such demorphing techniques. In this paper, we first analyze the shortcomings of the demorphing metrics currently used in the literature. We then propose a new metric called biometrically cross-weighted IQA that overcomes these issues and extensively benchmark current methods on the proposed metric to show its efficacy. Experiments on three existing demorphing methods and six datasets on two commonly used face matchers validate the efficacy of our proposed metric.
dc-GAN: Dual-Conditioned GAN for Face Demorphing From a Single Morph
Nov 20, 2024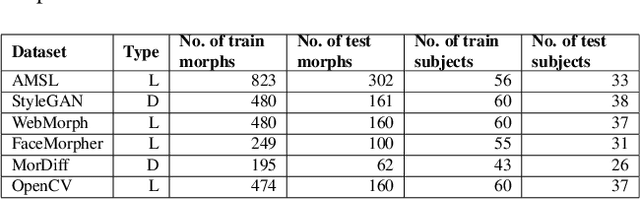

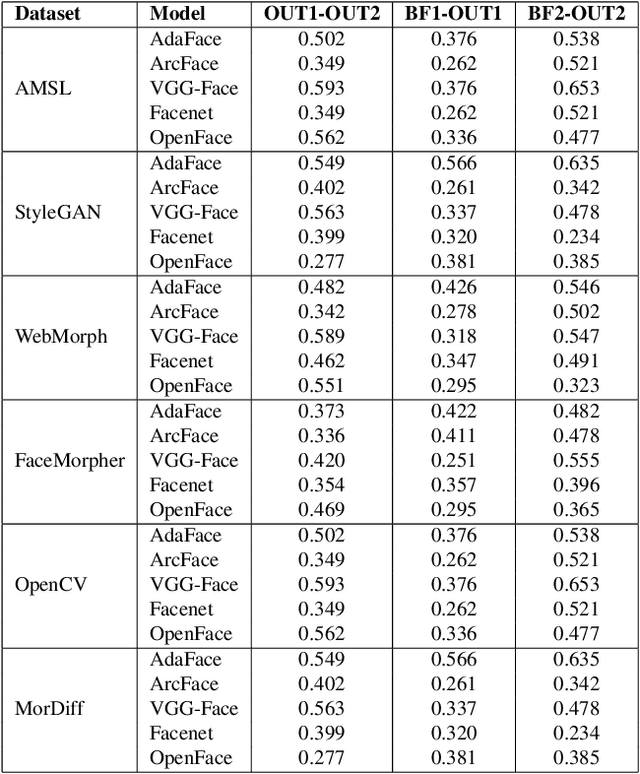
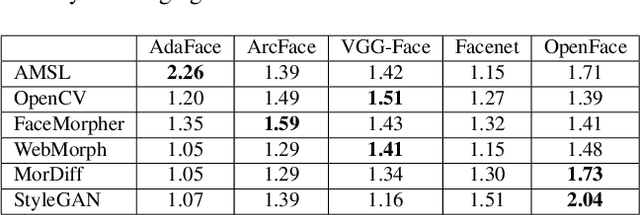
A facial morph is an image created by combining two face images pertaining to two distinct identities. Face demorphing inverts the process and tries to recover the original images constituting a facial morph. While morph attack detection (MAD) techniques can be used to flag morph images, they do not divulge any visual information about the faces used to create them. Demorphing helps address this problem. Existing demorphing techniques are either very restrictive (assume identities during testing) or produce feeble outputs (both outputs look very similar). In this paper, we overcome these issues by proposing dc-GAN, a novel GAN-based demorphing method conditioned on the morph images. Our method overcomes morph-replication and produces high quality reconstructions of the bonafide images used to create the morphs. Moreover, our method is highly generalizable across demorphing paradigms (differential/reference-free). We conduct experiments on AMSL, FRLL-Morphs and MorDiff datasets to showcase the efficacy of our method.
Facial Demorphing via Identity Preserving Image Decomposition
Aug 20, 2024A face morph is created by combining the face images usually pertaining to two distinct identities. The goal is to generate an image that can be matched with two identities thereby undermining the security of a face recognition system. To deal with this problem, several morph attack detection techniques have been developed. But these methods do not extract any information about the underlying bonafides used to create them. Demorphing addresses this limitation. However, current demorphing techniques are mostly reference-based, i.e, they need an image of one of the identities to recover the other. In this work, we treat demorphing as an ill-posed decomposition problem. We propose a novel method that is reference-free and recovers the bonafides with high accuracy. Our method decomposes the morph into several identity-preserving feature components. A merger network then weighs and combines these components to recover the bonafides. Our method is observed to reconstruct high-quality bonafides in terms of definition and fidelity. Experiments on the CASIA-WebFace, SMDD and AMSL datasets demonstrate the effectiveness of our method.
SDeMorph: Towards Better Facial De-morphing from Single Morph
Aug 22, 2023Face Recognition Systems (FRS) are vulnerable to morph attacks. A face morph is created by combining multiple identities with the intention to fool FRS and making it match the morph with multiple identities. Current Morph Attack Detection (MAD) can detect the morph but are unable to recover the identities used to create the morph with satisfactory outcomes. Existing work in de-morphing is mostly reference-based, i.e. they require the availability of one identity to recover the other. Sudipta et al. \cite{ref9} proposed a reference-free de-morphing technique but the visual realism of outputs produced were feeble. In this work, we propose SDeMorph (Stably Diffused De-morpher), a novel de-morphing method that is reference-free and recovers the identities of bona fides. Our method produces feature-rich outputs that are of significantly high quality in terms of definition and facial fidelity. Our method utilizes Denoising Diffusion Probabilistic Models (DDPM) by destroying the input morphed signal and then reconstructing it back using a branched-UNet. Experiments on ASML, FRLL-FaceMorph, FRLL-MorDIFF, and SMDD datasets support the effectiveness of the proposed method.
Generating Adversarial Attacks in the Latent Space
Apr 10, 2023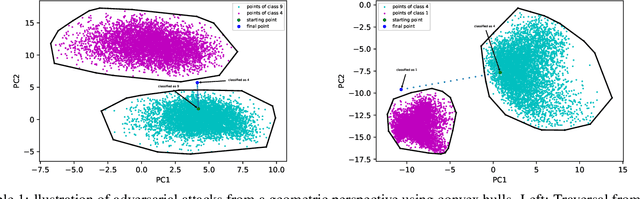


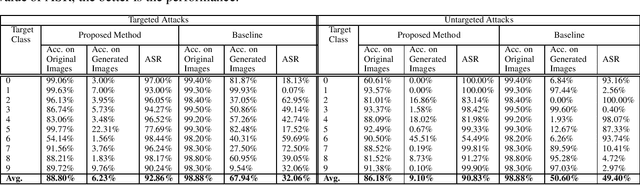
Adversarial attacks in the input (pixel) space typically incorporate noise margins such as $L_1$ or $L_{\infty}$-norm to produce imperceptibly perturbed data that confound deep learning networks. Such noise margins confine the magnitude of permissible noise. In this work, we propose injecting adversarial perturbations in the latent (feature) space using a generative adversarial network, removing the need for margin-based priors. Experiments on MNIST, CIFAR10, Fashion-MNIST, CIFAR100 and Stanford Dogs datasets support the effectiveness of the proposed method in generating adversarial attacks in the latent space while ensuring a high degree of visual realism with respect to pixel-based adversarial attack methods.
Efficient Mixed-Type Wafer Defect Pattern Recognition Using Compact Deformable Convolutional Transformers
Mar 24, 2023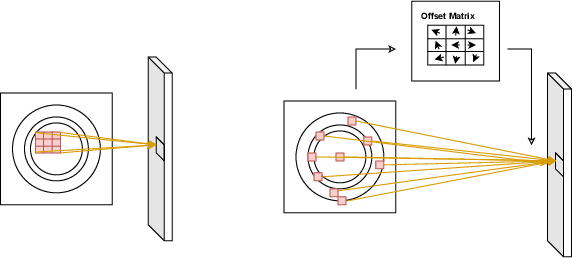


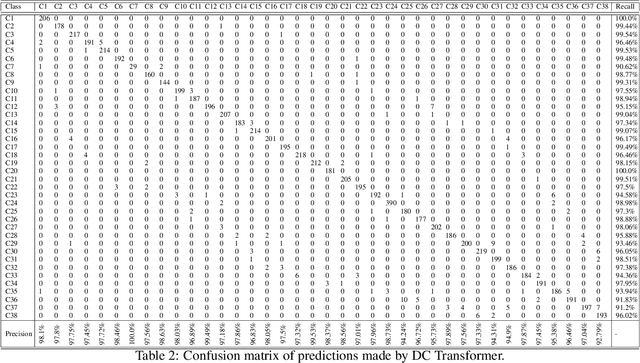
Manufacturing wafers is an intricate task involving thousands of steps. Defect Pattern Recognition (DPR) of wafer maps is crucial to find the root cause of the issue and further improving the yield in the wafer foundry. Mixed-type DPR is much more complicated compared to single-type DPR due to varied spatial features, the uncertainty of defects, and the number of defects present. To accurately predict the number of defects as well as the types of defects, we propose a novel compact deformable convolutional transformer (DC Transformer). Specifically, DC Transformer focuses on the global features present in the wafer map by virtue of learnable deformable kernels and multi-head attention to the global features. The proposed method succinctly models the internal relationship between the wafer maps and the defects. DC Transformer is evaluated on a real dataset containing 38 defect patterns. Experimental results show that DC Transformer performs exceptionally well in recognizing both single and mixed-type defects. The proposed method outperforms the current state of the models by a considerable margin