 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultibit Tries Packet Classification with Deep Reinforcement Learning
May 17, 2022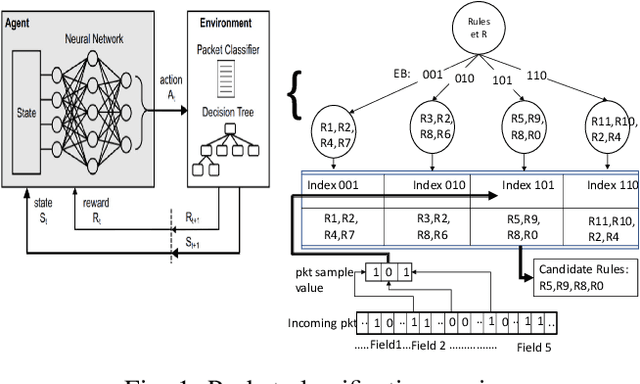
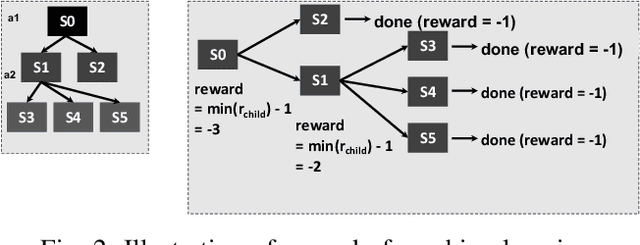
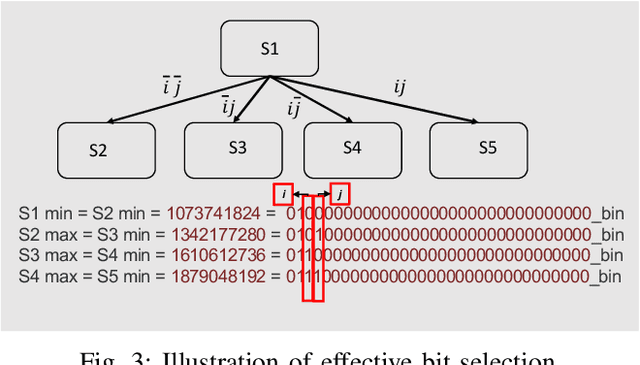
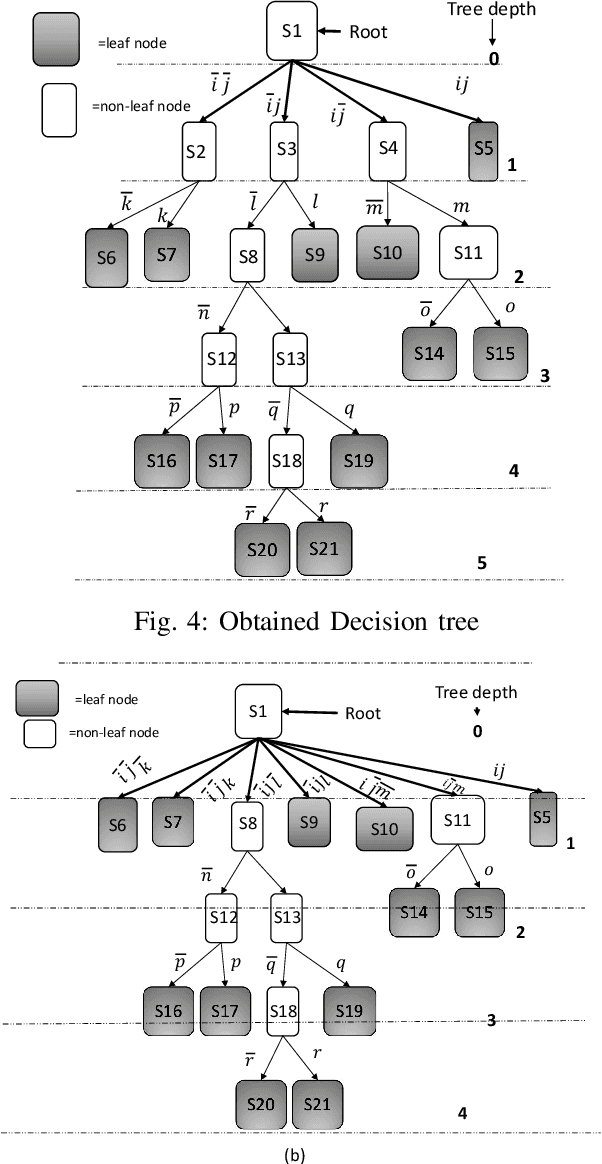
High performance packet classification is a key component to support scalable network applications like firewalls, intrusion detection, and differentiated services. With ever increasing in the line-rate in core networks, it becomes a great challenge to design a scalable and high performance packet classification solution using hand-tuned heuristics approaches. In this paper, we present a scalable learning-based packet classification engine and its performance evaluation. By exploiting the sparsity of ruleset, our algorithm uses a few effective bits (EBs) to extract a large number of candidate rules with just a few of memory access. These effective bits are learned with deep reinforcement learning and they are used to create a bitmap to filter out the majority of rules which do not need to be full-matched to improve the online system performance. Moreover, our EBs learning-based selection method is independent of the ruleset, which can be applied to varying rulesets. Our multibit tries classification engine outperforms lookup time both in worst and average case by 55% and reduce memory footprint, compared to traditional decision tree without EBs.
* 6 pages. arXiv admin note: text overlap with arXiv:2205.07973
Many Field Packet Classification with Decomposition and Reinforcement Learning
May 16, 2022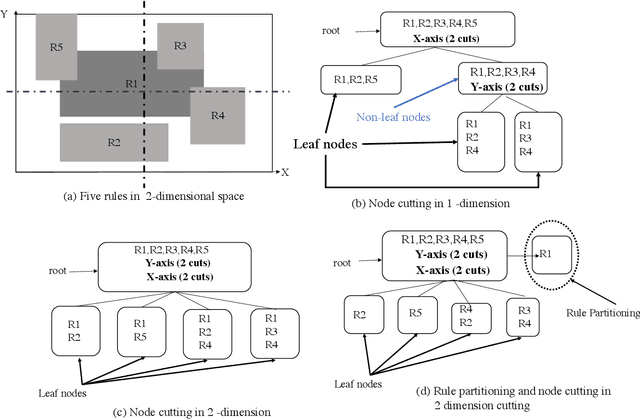
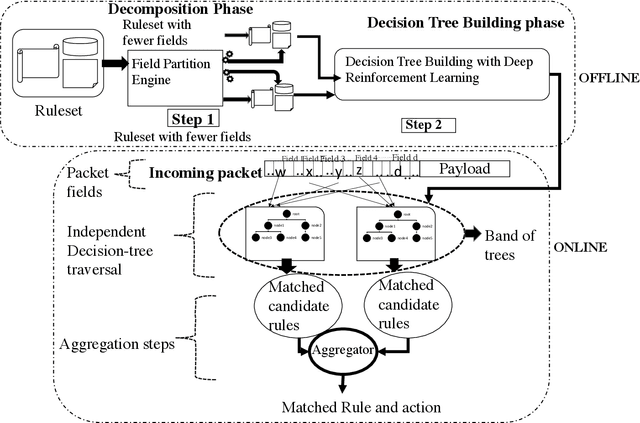

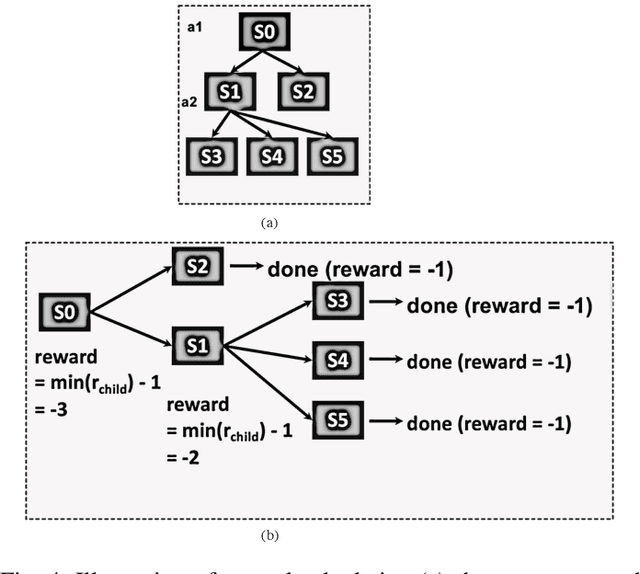
Scalable packet classification is a key requirement to support scalable network applications like firewalls, intrusion detection, and differentiated services. With ever increasing in the line-rate in core networks, it becomes a great challenge to design a scalable packet classification solution using hand-tuned heuristics approaches. In this paper, we present a scalable learning-based packet classification engine by building an efficient data structure for different ruleset with many fields. Our method consists of the decomposition of fields into subsets and building separate decision trees on those subsets using a deep reinforcement learning procedure. To decompose given fields of a ruleset, we consider different grouping metrics like standard deviation of individual fields and introduce a novel metric called diversity index (DI). We examine different decomposition schemes and construct decision trees for each scheme using deep reinforcement learning and compare the results. The results show that the SD decomposition metrics results in 11.5% faster than DI metrics, 25% faster than random 2 and 40% faster than random 1. Furthermore, our learning-based selection method can be applied to varying rulesets due to its ruleset independence.
* 13 pages, published in IET Netw. arXiv admin note: substantial text overlap with arXiv:1902.10319 by other authors