 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Cloud Based Scene Segmentation: A Survey
Mar 16, 2025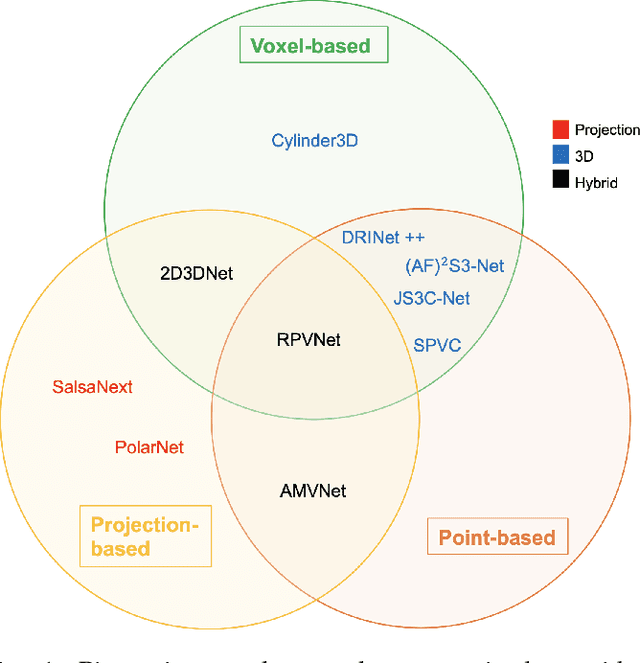
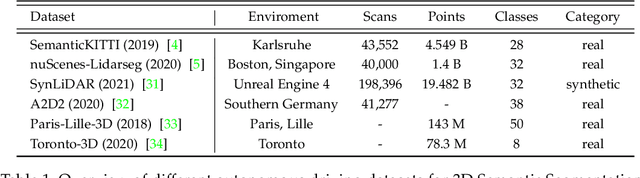

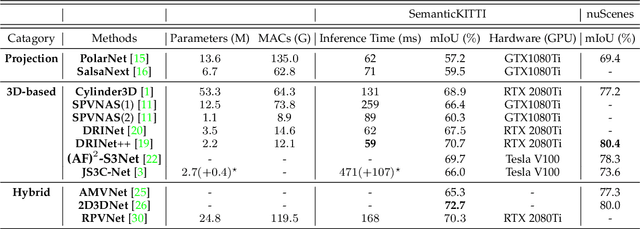
Autonomous driving is a safety-critical application, and it is therefore a top priority that the accompanying assistance systems are able to provide precise information about the surrounding environment of the vehicle. Tasks such as 3D Object Detection deliver an insufficiently detailed understanding of the surrounding scene because they only predict a bounding box for foreground objects. In contrast, 3D Semantic Segmentation provides richer and denser information about the environment by assigning a label to each individual point, which is of paramount importance for autonomous driving tasks, such as navigation or lane changes. To inspire future research, in this review paper, we provide a comprehensive overview of the current state-of-the-art methods in the field of Point Cloud Semantic Segmentation for autonomous driving. We categorize the approaches into projection-based, 3D-based and hybrid methods. Moreover, we discuss the most important and commonly used datasets for this task and also emphasize the importance of synthetic data to support research when real-world data is limited. We further present the results of the different methods and compare them with respect to their segmentation accuracy and efficiency.