 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHarvest: Opportunistic Peer-to-Peer GPU Caching for LLM Inference
Jan 30, 2026Large Language Model (LLM) inference is increasingly constrained by GPU memory capacity rather than compute throughput, driven by growing model sizes and the linear growth of the key-value (KV) cache during autoregressive decoding. Existing approaches mitigate memory pressure by offloading model state and KV tensors to host memory, but incur substantial latency due to limited PCIe bandwidth. We present Harvest, an opportunistic GPU cache management framework that exploits high-bandwidth peer-to-peer GPU interconnects to dynamically place model weights and KV cache in unused GPU memory. Harvest treats peer GPU memory as a transient cache tier, preserving correctness while reducing data movement overhead under dynamic memory availability. We demonstrate significant throughput speedup of more than 2 times by using Harvest to accelerate the retrieval of two widely-used inference components: expert layer weights and KV cache entries.
Support-BERT: Predicting Quality of Question-Answer Pairs in MSDN using Deep Bidirectional Transformer
May 17, 2020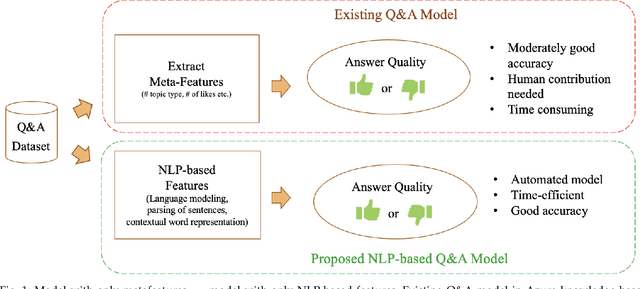

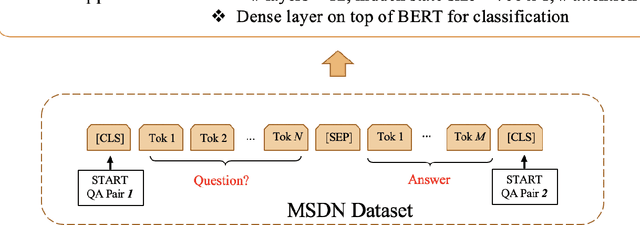

Quality of questions and answers from community support websites (e.g. Microsoft Developers Network, Stackoverflow, Github, etc.) is difficult to define and a prediction model of quality questions and answers is even more challenging to implement. Previous works have addressed the question quality models and answer quality models separately using meta-features like number of up-votes, trustworthiness of the person posting the questions or answers, titles of the post, and context naive natural language processing features. However, there is a lack of an integrated question-answer quality model for community question answering websites in the literature. In this brief paper, we tackle the quality Q&A modeling problems from the community support websites using a recently developed deep learning model using bidirectional transformers. We investigate the applicability of transfer learning on Q&A quality modeling using Bidirectional Encoder Representations from Transformers (BERT) trained on a separate tasks originally using Wikipedia. It is found that a further pre-training of BERT model along with finetuning on the Q&As extracted from Microsoft Developer Network (MSDN) can boost the performance of automated quality prediction to more than 80%. Furthermore, the implementations are carried out for deploying the finetuned model in real-time scenario using AzureML in Azure knowledge base system.