 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePartAL: Efficient Partial Active Learning in Multi-Task Visual Settings
Nov 21, 2022



Multi-task learning is central to many real-world applications. Unfortunately, obtaining labelled data for all tasks is time-consuming, challenging, and expensive. Active Learning (AL) can be used to reduce this burden. Existing techniques typically involve picking images to be annotated and providing annotations for all tasks. In this paper, we show that it is more effective to select not only the images to be annotated but also a subset of tasks for which to provide annotations at each AL iteration. Furthermore, the annotations that are provided can be used to guess pseudo-labels for the tasks that remain unannotated. We demonstrate the effectiveness of our approach on several popular multi-task datasets.
ZigZag: Universal Sampling-free Uncertainty Estimation Through Two-Step Inference
Nov 21, 2022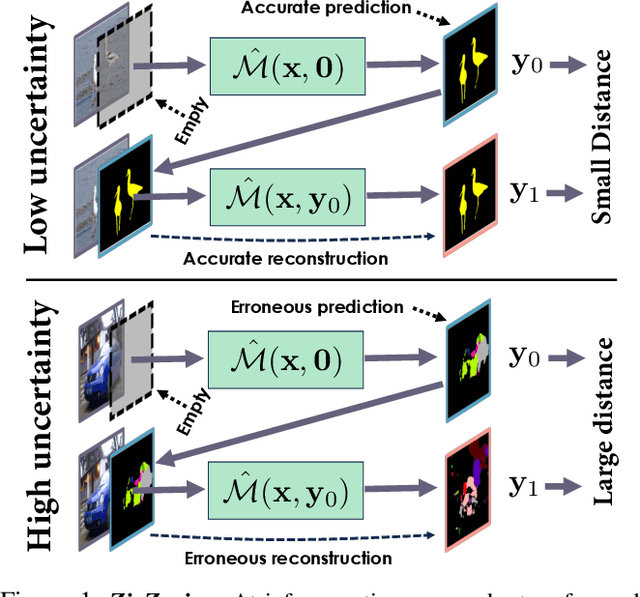
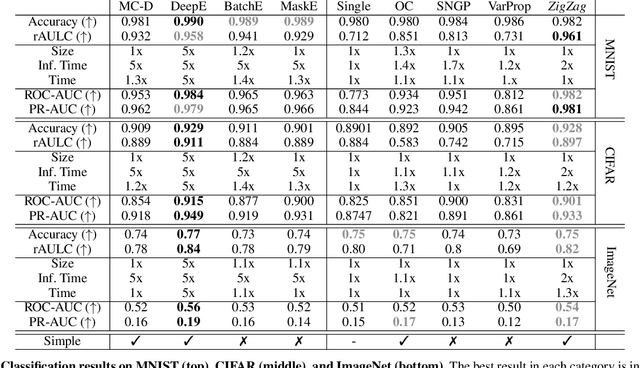
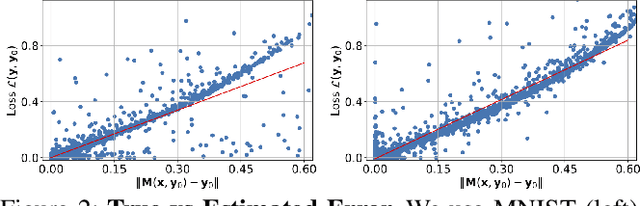
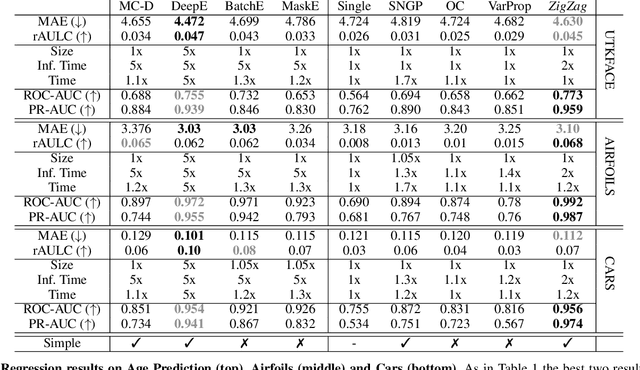
Whereas the ability of deep networks to produce useful predictions on many kinds of data has been amply demonstrated, estimating the reliability of these predictions remains challenging. Sampling approaches such as MC-Dropout and Deep Ensembles have emerged as the most popular ones for this purpose. Unfortunately, they require many forward passes at inference time, which slows them down. Sampling-free approaches can be faster but suffer from other drawbacks, such as lower reliability of uncertainty estimates, difficulty of use, and limited applicability to different types of tasks and data. In this work, we introduce a sampling-free approach that is generic and easy to deploy, while producing reliable uncertainty estimates on par with state-of-the-art methods at a significantly lower computational cost. It is predicated on training the network to produce the same output with and without additional information about that output. At inference time, when no prior information is given, we use the network's own prediction as the additional information. We prove that the difference between the two predictions is an accurate uncertainty estimate and demonstrate our approach on various types of tasks and applications.