 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAMbA: Speech enhancement with Asynchronous ad-hoc Microphone Arrays
Jul 31, 2023Speech enhancement in ad-hoc microphone arrays is often hindered by the asynchronization of the devices composing the microphone array. Asynchronization comes from sampling time offset and sampling rate offset which inevitably occur when the microphones are embedded in different hardware components. In this paper, we propose a deep neural network (DNN)-based speech enhancement solution that is suited for applications in ad-hoc microphone arrays because it is distributed and copes with asynchronization. We show that asynchronization has a limited impact on the spatial filtering and mostly affects the performance of the DNNs. Instead of resynchronising the signals, which requires costly processing steps, we use an attention mechanism which makes the DNNs, thus our whole pipeline, robust to asynchronization. We also show that the attention mechanism leads to the asynchronization parameters in an unsupervised manner.
Attention-based distributed speech enhancement for unconstrained microphone arrays with varying number of nodes
Jun 15, 2021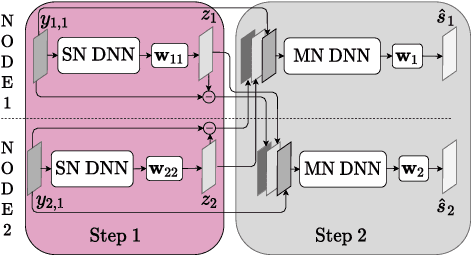
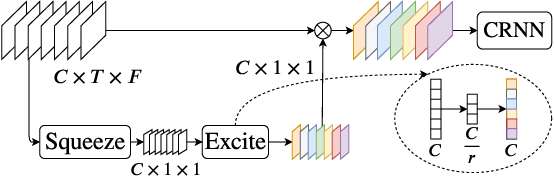
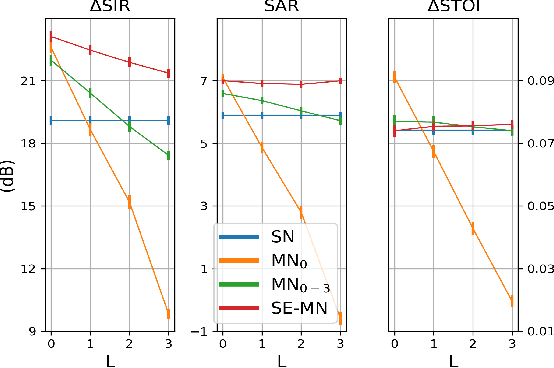
Speech enhancement promises higher efficiency in ad-hoc microphone arrays than in constrained microphone arrays thanks to the wide spatial coverage of the devices in the acoustic scene. However, speech enhancement in ad-hoc microphone arrays still raises many challenges. In particular, the algorithms should be able to handle a variable number of microphones, as some devices in the array might appear or disappear. In this paper, we propose a solution that can efficiently process the spatial information captured by the different devices of the microphone array, while being robust to a link failure. To do this, we use an attention mechanism in order to put more weight on the relevant signals sent throughout the array and to neglect the redundant or empty channels.
DNN-Based Distributed Multichannel Mask Estimation for Speech Enhancement in Microphone Arrays
Mar 16, 2020

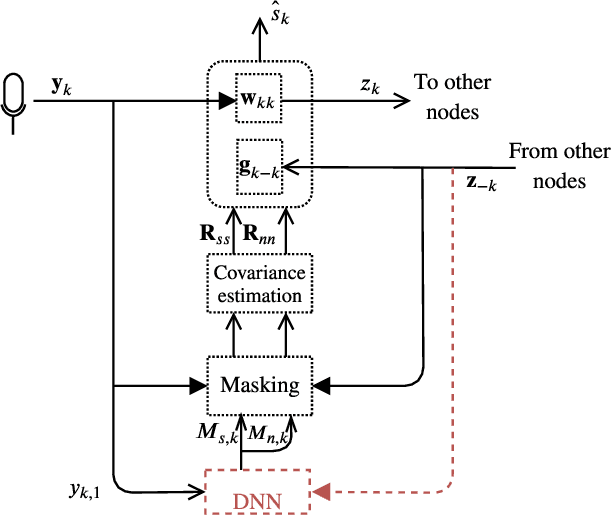

Multichannel processing is widely used for speech enhancement but several limitations appear when trying to deploy these solutions to the real-world. Distributed sensor arrays that consider several devices with a few microphones is a viable alternative that allows for exploiting the multiple devices equipped with microphones that we are using in our everyday life. In this context, we propose to extend the distributed adaptive node-specific signal estimation approach to a neural networks framework. At each node, a local filtering is performed to send one signal to the other nodes where a mask is estimated by a neural network in order to compute a global multi-channel Wiener filter. In an array of two nodes, we show that this additional signal can be efficiently taken into account to predict the masks and leads to better speech enhancement performances than when the mask estimation relies only on the local signals.
* Submitted to ICASSP2020