 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLPASS: Linear Probes as Stepping Stones for vulnerability detection using compressed LLMs
May 30, 2025Large Language Models (LLMs) are being extensively used for cybersecurity purposes. One of them is the detection of vulnerable codes. For the sake of efficiency and effectiveness, compression and fine-tuning techniques are being developed, respectively. However, they involve spending substantial computational efforts. In this vein, we analyse how Linear Probes (LPs) can be used to provide an estimation on the performance of a compressed LLM at an early phase -- before fine-tuning. We also show their suitability to set the cut-off point when applying layer pruning compression. Our approach, dubbed $LPASS$, is applied in BERT and Gemma for the detection of 12 of MITRE's Top 25 most dangerous vulnerabilities on 480k C/C++ samples. LPs can be computed in 142.97 s. and provide key findings: (1) 33.3 \% and 72.2\% of layers can be removed, respectively, with no precision loss; (2) they provide an early estimate of the post-fine-tuning and post-compression model effectiveness, with 3\% and 8.68\% as the lowest and average precision errors, respectively. $LPASS$-based LLMs outperform the state of the art, reaching 86.9\% of accuracy in multi-class vulnerability detection. Interestingly, $LPASS$-based compressed versions of Gemma outperform the original ones by 1.6\% of F1-score at a maximum while saving 29.4 \% and 23.8\% of training and inference time and 42.98\% of model size.
LUMIA: Linear probing for Unimodal and MultiModal Membership Inference Attacks leveraging internal LLM states
Dec 02, 2024Large Language Models (LLMs) are increasingly used in a variety of applications, but concerns around membership inference have grown in parallel. Previous efforts focus on black-to-grey-box models, thus neglecting the potential benefit from internal LLM information. To address this, we propose the use of Linear Probes (LPs) as a method to detect Membership Inference Attacks (MIAs) by examining internal activations of LLMs. Our approach, dubbed LUMIA, applies LPs layer-by-layer to get fine-grained data on the model inner workings. We test this method across several model architectures, sizes and datasets, including unimodal and multimodal tasks. In unimodal MIA, LUMIA achieves an average gain of 15.71 % in Area Under the Curve (AUC) over previous techniques. Remarkably, LUMIA reaches AUC>60% in 65.33% of cases -- an increment of 46.80% against the state of the art. Furthermore, our approach reveals key insights, such as the model layers where MIAs are most detectable. In multimodal models, LPs indicate that visual inputs can significantly contribute to detect MIAs -- AUC>60% is reached in 85.90% of experiments.
Mitigating Leakage from Data Dependent Communications in Decentralized Computing using Differential Privacy
Dec 23, 2021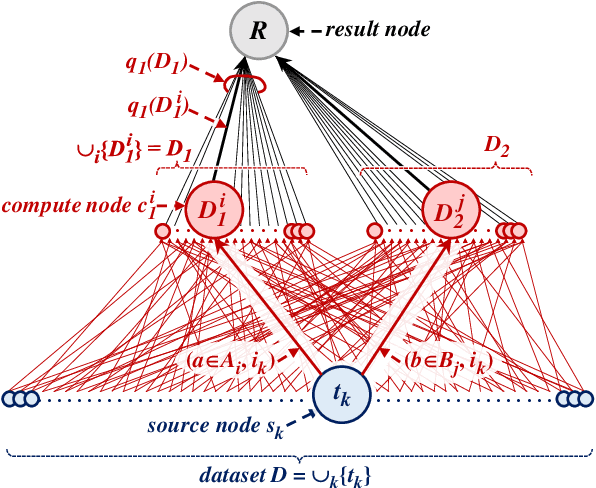

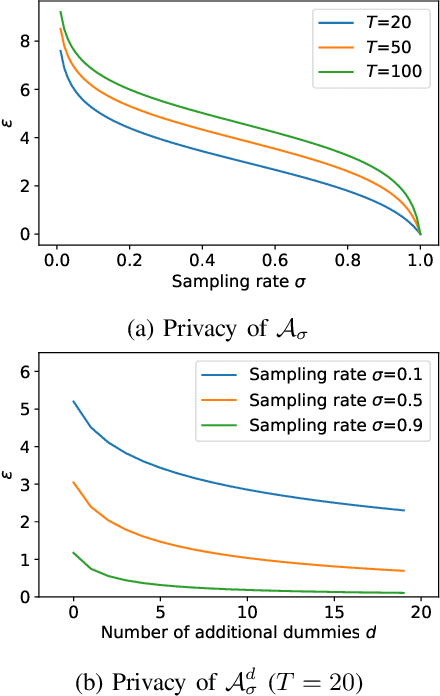

Imagine a group of citizens willing to collectively contribute their personal data for the common good to produce socially useful information, resulting from data analytics or machine learning computations. Sharing raw personal data with a centralized server performing the computation could raise concerns about privacy and a perceived risk of mass surveillance. Instead, citizens may trust each other and their own devices to engage into a decentralized computation to collaboratively produce an aggregate data release to be shared. In the context of secure computing nodes exchanging messages over secure channels at runtime, a key security issue is to protect against external attackers observing the traffic, whose dependence on data may reveal personal information. Existing solutions are designed for the cloud setting, with the goal of hiding all properties of the underlying dataset, and do not address the specific privacy and efficiency challenges that arise in the above context. In this paper, we define a general execution model to control the data-dependence of communications in user-side decentralized computations, in which differential privacy guarantees for communication patterns in global execution plans can be analyzed by combining guarantees obtained on local clusters of nodes. We propose a set of algorithms which allow to trade-off between privacy, utility and efficiency. Our formal privacy guarantees leverage and extend recent results on privacy amplification by shuffling. We illustrate the usefulness of our proposal on two representative examples of decentralized execution plans with data-dependent communications.