 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRED: Deep Recurrent Neural Networks for Sleep EEG Event Detection
May 15, 2020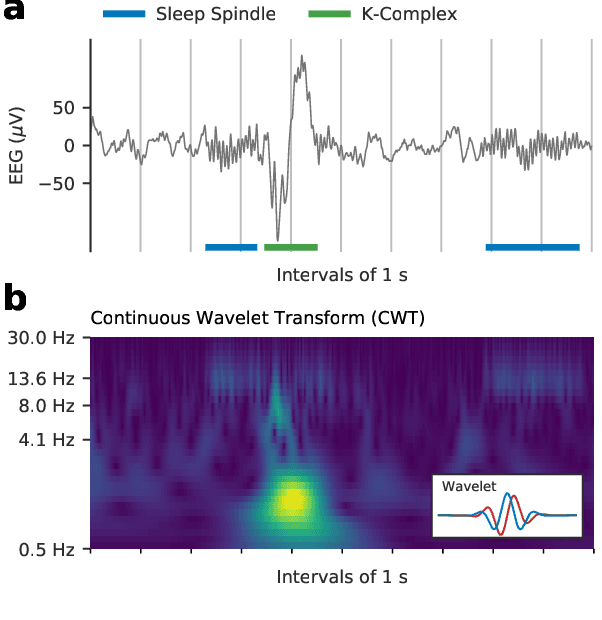
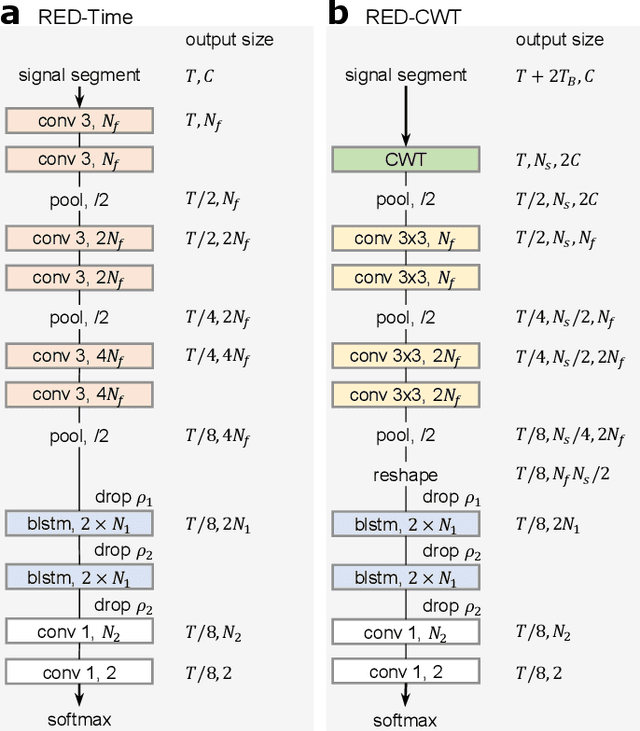
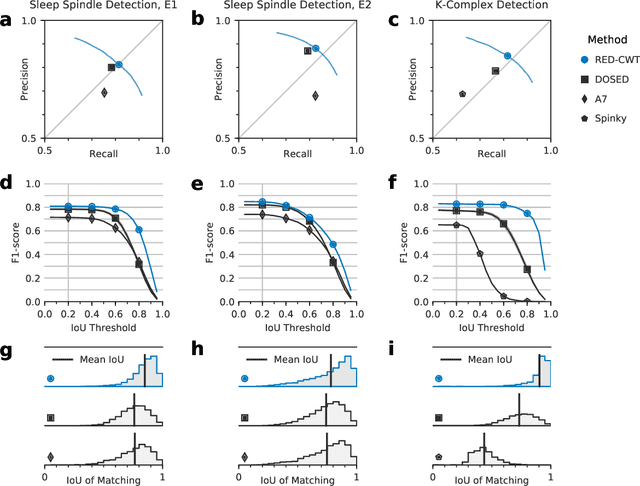
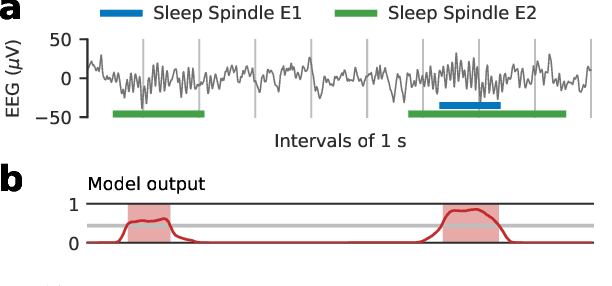
The brain electrical activity presents several short events during sleep that can be observed as distinctive micro-structures in the electroencephalogram (EEG), such as sleep spindles and K-complexes. These events have been associated with biological processes and neurological disorders, making them a research topic in sleep medicine. However, manual detection limits their study because it is time-consuming and affected by significant inter-expert variability, motivating automatic approaches. We propose a deep learning approach based on convolutional and recurrent neural networks for sleep EEG event detection called Recurrent Event Detector (RED). RED uses one of two input representations: a) the time-domain EEG signal, or b) a complex spectrogram of the signal obtained with the Continuous Wavelet Transform (CWT). Unlike previous approaches, a fixed time window is avoided and temporal context is integrated to better emulate the visual criteria of experts. When evaluated on the MASS dataset, our detectors outperform the state of the art in both sleep spindle and K-complex detection with a mean F1-score of at least 80.9% and 82.6%, respectively. Although the CWT-domain model obtained a similar performance than its time-domain counterpart, the former allows in principle a more interpretable input representation due to the use of a spectrogram. The proposed approach is event-agnostic and can be used directly to detect other types of sleep events.
On the Information Plane of Autoencoders
May 15, 2020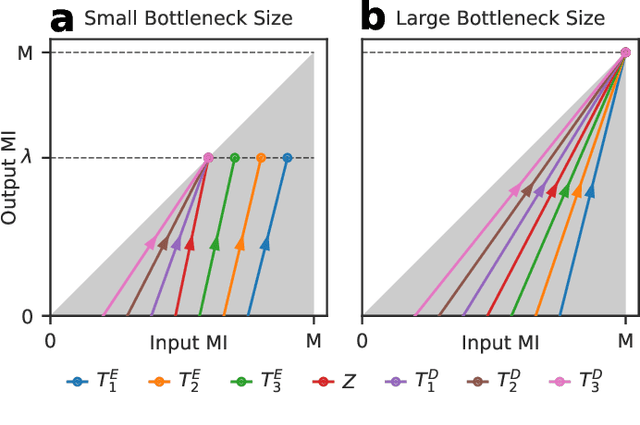


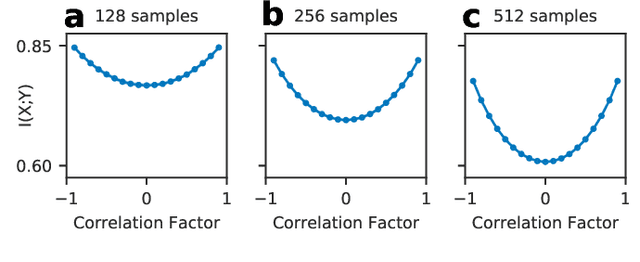
The training dynamics of hidden layers in deep learning are poorly understood in theory. Recently, the Information Plane (IP) was proposed to analyze them, which is based on the information-theoretic concept of mutual information (MI). The Information Bottleneck (IB) theory predicts that layers maximize relevant information and compress irrelevant information. Due to the limitations in MI estimation from samples, there is an ongoing debate about the properties of the IP for the supervised learning case. In this work, we derive a theoretical convergence for the IP of autoencoders. The theory predicts that ideal autoencoders with a large bottleneck layer size do not compress input information, whereas a small size causes compression only in the encoder layers. For the experiments, we use a Gram-matrix based MI estimator recently proposed in the literature. We propose a new rule to adjust its parameters that compensates scale and dimensionality effects. Using our proposed rule, we obtain experimental IPs closer to the theory. Our theoretical IP for autoencoders could be used as a benchmark to validate new methods to estimate MI in neural networks. In this way, experimental limitations could be recognized and corrected, helping with the ongoing debate on the supervised learning case.