 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the Information Plane of Autoencoders
Paper and Code
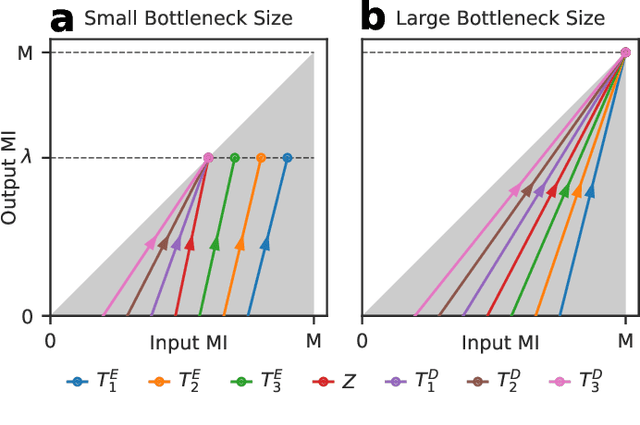


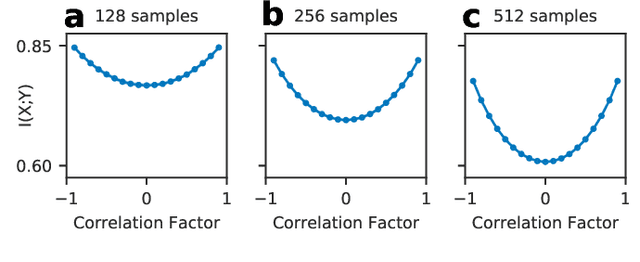
The training dynamics of hidden layers in deep learning are poorly understood in theory. Recently, the Information Plane (IP) was proposed to analyze them, which is based on the information-theoretic concept of mutual information (MI). The Information Bottleneck (IB) theory predicts that layers maximize relevant information and compress irrelevant information. Due to the limitations in MI estimation from samples, there is an ongoing debate about the properties of the IP for the supervised learning case. In this work, we derive a theoretical convergence for the IP of autoencoders. The theory predicts that ideal autoencoders with a large bottleneck layer size do not compress input information, whereas a small size causes compression only in the encoder layers. For the experiments, we use a Gram-matrix based MI estimator recently proposed in the literature. We propose a new rule to adjust its parameters that compensates scale and dimensionality effects. Using our proposed rule, we obtain experimental IPs closer to the theory. Our theoretical IP for autoencoders could be used as a benchmark to validate new methods to estimate MI in neural networks. In this way, experimental limitations could be recognized and corrected, helping with the ongoing debate on the supervised learning case.