 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning on Human Decision Models for Uniquely Collaborative AI Teammates
Nov 18, 2021



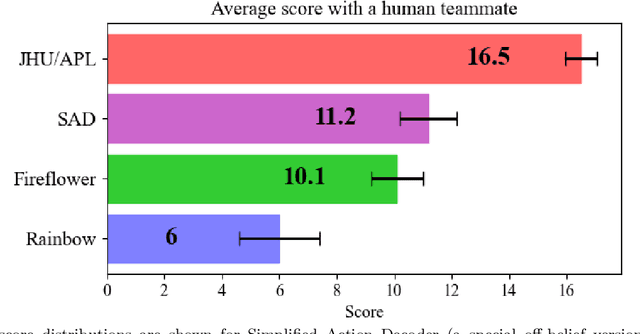
In 2021 the Johns Hopkins University Applied Physics Laboratory held an internal challenge to develop artificially intelligent (AI) agents that could excel at the collaborative card game Hanabi. Agents were evaluated on their ability to play with human players whom the agents had never previously encountered. This study details the development of the agent that won the challenge by achieving a human-play average score of 16.5, outperforming the current state-of-the-art for human-bot Hanabi scores. The winning agent's development consisted of observing and accurately modeling the author's decision making in Hanabi, then training with a behavioral clone of the author. Notably, the agent discovered a human-complementary play style by first mimicking human decision making, then exploring variations to the human-like strategy that led to higher simulated human-bot scores. This work examines in detail the design and implementation of this human compatible Hanabi teammate, as well as the existence and implications of human-complementary strategies and how they may be explored for more successful applications of AI in human machine teams.
Instructive artificial intelligence (AI) for human training, assistance, and explainability
Nov 02, 2021

We propose a novel approach to explainable AI (XAI) based on the concept of "instruction" from neural networks. In this case study, we demonstrate how a superhuman neural network might instruct human trainees as an alternative to traditional approaches to XAI. Specifically, an AI examines human actions and calculates variations on the human strategy that lead to better performance. Experiments with a JHU/APL-developed AI player for the cooperative card game Hanabi suggest this technique makes unique contributions to explainability while improving human performance. One area of focus for Instructive AI is in the significant discrepancies that can arise between a human's actual strategy and the strategy they profess to use. This inaccurate self-assessment presents a barrier for XAI, since explanations of an AI's strategy may not be properly understood or implemented by human recipients. We have developed and are testing a novel, Instructive AI approach that estimates human strategy by observing human actions. With neural networks, this allows a direct calculation of the changes in weights needed to improve the human strategy to better emulate a more successful AI. Subjected to constraints (e.g. sparsity) these weight changes can be interpreted as recommended changes to human strategy (e.g. "value A more, and value B less"). Instruction from AI such as this functions both to help humans perform better at tasks, but also to better understand, anticipate, and correct the actions of an AI. Results will be presented on AI instruction's ability to improve human decision-making and human-AI teaming in Hanabi.