 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLayered SGD: A Decentralized and Synchronous SGD Algorithm for Scalable Deep Neural Network Training
Jun 13, 2019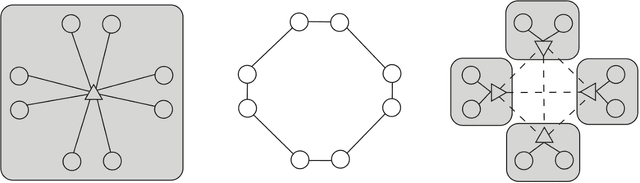
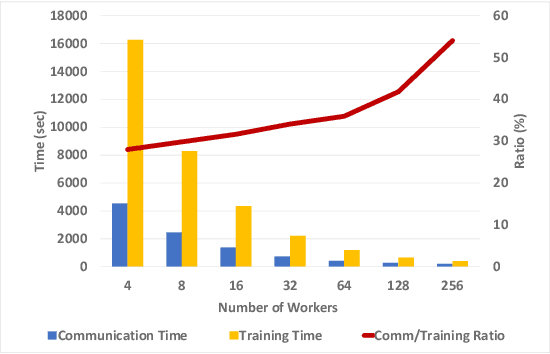
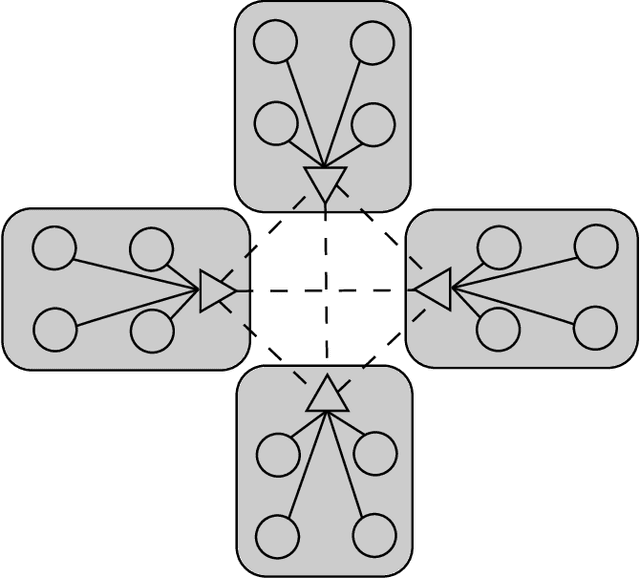
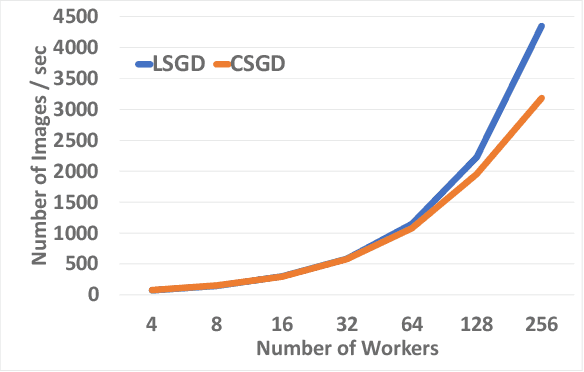
Stochastic Gradient Descent (SGD) is the most popular algorithm for training deep neural networks (DNNs). As larger networks and datasets cause longer training times, training on distributed systems is common and distributed SGD variants, mainly asynchronous and synchronous SGD, are widely used. Asynchronous SGD is communication efficient but suffers from accuracy degradation due to delayed parameter updating. Synchronous SGD becomes communication intensive when the number of nodes increases regardless of its advantage. To address these issues, we introduce Layered SGD (LSGD), a new decentralized synchronous SGD algorithm. LSGD partitions computing resources into subgroups that each contain a communication layer (communicator) and a computation layer (worker). Each subgroup has centralized communication for parameter updates while communication between subgroups is handled by communicators. As a result, communication time is overlapped with I/O latency of workers. The efficiency of the algorithm is tested by training a deep network on the ImageNet classification task.