 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEscaping Plato's Cave: Robust Conceptual Reasoning through Interpretable 3D Neural Object Volumes
Mar 17, 2025With the rise of neural networks, especially in high-stakes applications, these networks need two properties (i) robustness and (ii) interpretability to ensure their safety. Recent advances in classifiers with 3D volumetric object representations have demonstrated a greatly enhanced robustness in out-of-distribution data. However, these 3D-aware classifiers have not been studied from the perspective of interpretability. We introduce CAVE - Concept Aware Volumes for Explanations - a new direction that unifies interpretability and robustness in image classification. We design an inherently-interpretable and robust classifier by extending existing 3D-aware classifiers with concepts extracted from their volumetric representations for classification. In an array of quantitative metrics for interpretability, we compare against different concept-based approaches across the explainable AI literature and show that CAVE discovers well-grounded concepts that are used consistently across images, while achieving superior robustness.
H-POPE: Hierarchical Polling-based Probing Evaluation of Hallucinations in Large Vision-Language Models
Nov 06, 2024



By leveraging both texts and images, large vision language models (LVLMs) have shown significant progress in various multi-modal tasks. Nevertheless, these models often suffer from hallucinations, e.g., they exhibit inconsistencies between the visual input and the textual output. To address this, we propose H-POPE, a coarse-to-fine-grained benchmark that systematically assesses hallucination in object existence and attributes. Our evaluation shows that models are prone to hallucinations on object existence, and even more so on fine-grained attributes. We further investigate whether these models rely on visual input to formulate the output texts.
Towards Better Inclusivity: A Diverse Tweet Corpus of English Varieties
Jan 21, 2024
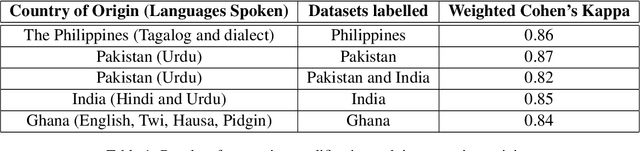


The prevalence of social media presents a growing opportunity to collect and analyse examples of English varieties. Whilst usage of these varieties was - and, in many cases, still is - used only in spoken contexts or hard-to-access private messages, social media sites like Twitter provide a platform for users to communicate informally in a scrapeable format. Notably, Indian English (Hinglish), Singaporean English (Singlish), and African-American English (AAE) can be commonly found online. These varieties pose a challenge to existing natural language processing (NLP) tools as they often differ orthographically and syntactically from standard English for which the majority of these tools are built. NLP models trained on standard English texts produced biased outcomes for users of underrepresented varieties. Some research has aimed to overcome the inherent biases caused by unrepresentative data through techniques like data augmentation or adjusting training models. We aim to address the issue of bias at its root - the data itself. We curate a dataset of tweets from countries with high proportions of underserved English variety speakers, and propose an annotation framework of six categorical classifications along a pseudo-spectrum that measures the degree of standard English and that thereby indirectly aims to surface the manifestations of English varieties in these tweets. Following best annotation practices, our growing corpus features 170,800 tweets taken from 7 countries, labeled by annotators who are from those countries and can communicate in regionally-dominant varieties of English. Our corpus highlights the accuracy discrepancies in pre-trained language identifiers between western English and non-western (i.e., less standard) English varieties. We hope to contribute to the growing literature identifying and reducing the implicit demographic discrepancies in NLP.