 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValid Inference for Machine Learning Model Parameters
Feb 21, 2023The parameters of a machine learning model are typically learned by minimizing a loss function on a set of training data. However, this can come with the risk of overtraining; in order for the model to generalize well, it is of great importance that we are able to find the optimal parameter for the model on the entire population -- not only on the given training sample. In this paper, we construct valid confidence sets for this optimal parameter of a machine learning model, which can be generated using only the training data without any knowledge of the population. We then show that studying the distribution of this confidence set allows us to assign a notion of confidence to arbitrary regions of the parameter space, and we demonstrate that this distribution can be well-approximated using bootstrapping techniques.
Conformal prediction for text infilling and part-of-speech prediction
Nov 04, 2021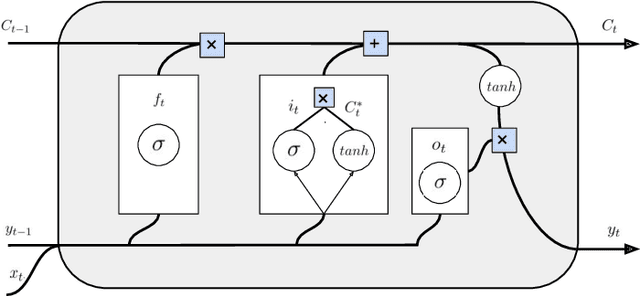

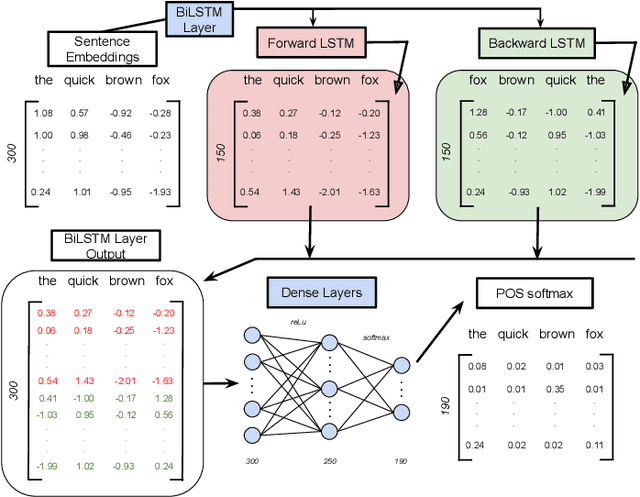
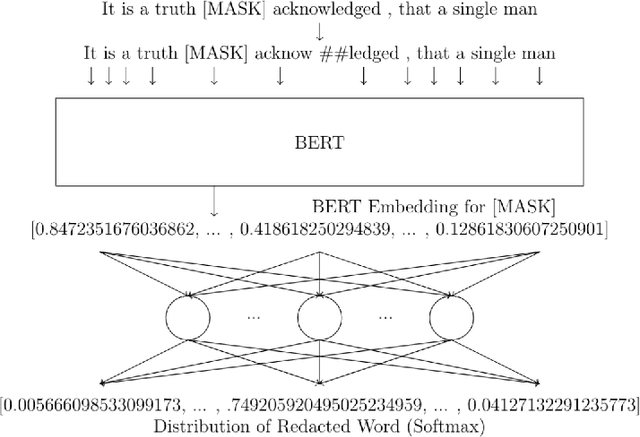
Modern machine learning algorithms are capable of providing remarkably accurate point-predictions; however, questions remain about their statistical reliability. Unlike conventional machine learning methods, conformal prediction algorithms return confidence sets (i.e., set-valued predictions) that correspond to a given significance level. Moreover, these confidence sets are valid in the sense that they guarantee finite sample control over type 1 error probabilities, allowing the practitioner to choose an acceptable error rate. In our paper, we propose inductive conformal prediction (ICP) algorithms for the tasks of text infilling and part-of-speech (POS) prediction for natural language data. We construct new conformal prediction-enhanced bidirectional encoder representations from transformers (BERT) and bidirectional long short-term memory (BiLSTM) algorithms for POS tagging and a new conformal prediction-enhanced BERT algorithm for text infilling. We analyze the performance of the algorithms in simulations using the Brown Corpus, which contains over 57,000 sentences. Our results demonstrate that the ICP algorithms are able to produce valid set-valued predictions that are small enough to be applicable in real-world applications. We also provide a real data example for how our proposed set-valued predictions can improve machine generated audio transcriptions.