 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExponentiated Gradient Reweighting for Robust Training Under Label Noise and Beyond
Apr 03, 2021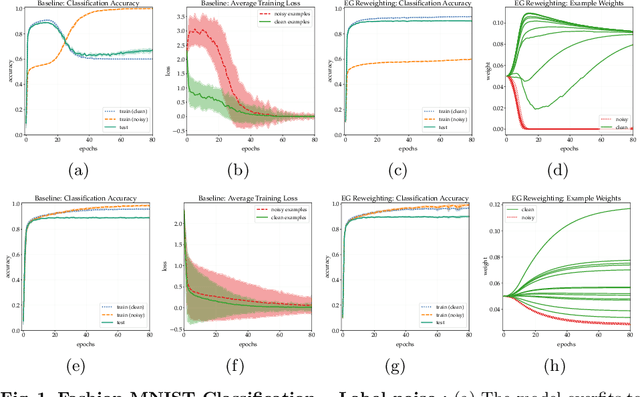
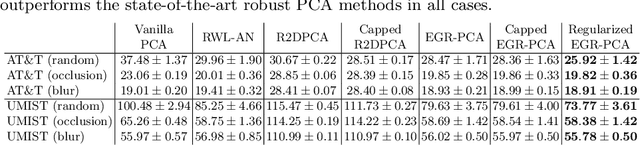
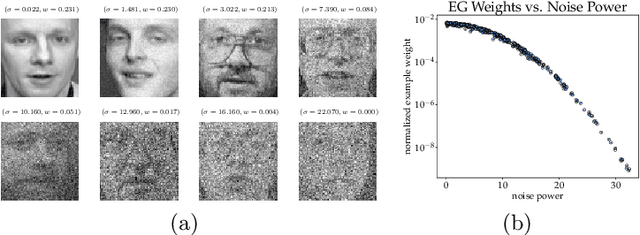

Many learning tasks in machine learning can be viewed as taking a gradient step towards minimizing the average loss of a batch of examples in each training iteration. When noise is prevalent in the data, this uniform treatment of examples can lead to overfitting to noisy examples with larger loss values and result in poor generalization. Inspired by the expert setting in on-line learning, we present a flexible approach to learning from noisy examples. Specifically, we treat each training example as an expert and maintain a distribution over all examples. We alternate between updating the parameters of the model using gradient descent and updating the example weights using the exponentiated gradient update. Unlike other related methods, our approach handles a general class of loss functions and can be applied to a wide range of noise types and applications. We show the efficacy of our approach for multiple learning settings, namely noisy principal component analysis and a variety of noisy classification problems.