 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCustomizing Spider Silk: Generative Models with Mechanical Property Conditioning for Protein Engineering
Apr 11, 2025The remarkable mechanical properties of spider silk, including its tensile strength and extensibility, are primarily governed by the repetitive regions of the proteins that constitute the fiber, the major ampullate spidroins (MaSps). However, establishing correlations between mechanical characteristics and repeat sequences is challenging due to the intricate sequence-structure-function relationships of MaSps and the limited availability of annotated datasets. In this study, we present a novel computational framework for designing MaSp repeat sequences with customizable mechanical properties. To achieve this, we developed a lightweight GPT-based generative model by distilling the pre-trained ProtGPT2 protein language model. The distilled model was subjected to multilevel fine-tuning using curated subsets of the Spider Silkome dataset. Specifically, we adapt the model for MaSp repeat generation using 6,000 MaSp repeat sequences and further refine it with 572 repeats associated with experimentally determined fiber-level mechanical properties. Our model generates biologically plausible MaSp repeat regions tailored to specific mechanical properties while also predicting those properties for given sequences. Validation includes sequence-level analysis, assessing physicochemical attributes and expected distribution of key motifs as well as secondary structure compositions. A correlation study using BLAST on the Spider Silkome dataset and a test set of MaSp repeats with known mechanical properties further confirmed the predictive accuracy of the model. This framework advances the rational design of spider silk-inspired biomaterials, offering a versatile tool for engineering protein sequences with tailored mechanical attributes.
RAZE: Region Guided Self-Supervised Gaze Representation Learning
Aug 05, 2022



Automatic eye gaze estimation is an important problem in vision based assistive technology with use cases in different emerging topics such as augmented reality, virtual reality and human-computer interaction. Over the past few years, there has been an increasing interest in unsupervised and self-supervised learning paradigms as it overcomes the requirement of large scale annotated data. In this paper, we propose RAZE, a Region guided self-supervised gAZE representation learning framework which leverage from non-annotated facial image data. RAZE learns gaze representation via auxiliary supervision i.e. pseudo-gaze zone classification where the objective is to classify visual field into different gaze zones (i.e. left, right and center) by leveraging the relative position of pupil-centers. Thus, we automatically annotate pseudo gaze zone labels of 154K web-crawled images and learn feature representations via `Ize-Net' framework. `Ize-Net' is a capsule layer based CNN architecture which can efficiently capture rich eye representation. The discriminative behaviour of the feature representation is evaluated on four benchmark datasets: CAVE, TabletGaze, MPII and RT-GENE. Additionally, we evaluate the generalizability of the proposed network on two other downstream task (i.e. driver gaze estimation and visual attention estimation) which demonstrate the effectiveness of the learnt eye gaze representation.
Unsupervised Learning of Eye Gaze Representation from the Web
Apr 04, 2019

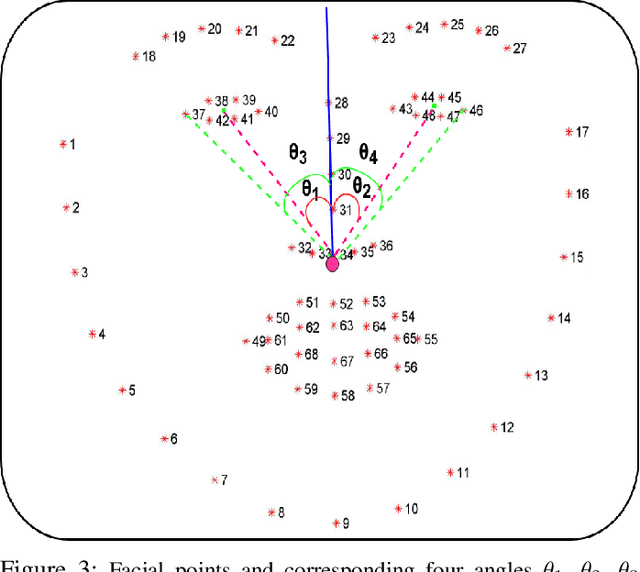

Automatic eye gaze estimation has interested researchers for a while now. In this paper, we propose an unsupervised learning based method for estimating the eye gaze region. To train the proposed network "Ize-Net" in self-supervised manner, we collect a large `in the wild' dataset containing 1,54,251 images from the web. For the images in the database, we divide the gaze into three regions based on an automatic technique based on pupil-centers localization and then use a feature-based technique to determine the gaze region. The performance is evaluated on the Tablet Gaze and CAVE datasets by fine-tuning results of Ize-Net for the task of eye gaze estimation. The feature representation learned is also used to train traditional machine learning algorithms for eye gaze estimation. The results demonstrate that the proposed method learns a rich data representation, which can be efficiently fine-tuned for any eye gaze estimation dataset.