 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSRTransGAN: Image Super-Resolution using Transformer based Generative Adversarial Network
Dec 04, 2023Image super-resolution aims to synthesize high-resolution image from a low-resolution image. It is an active area to overcome the resolution limitations in several applications like low-resolution object-recognition, medical image enhancement, etc. The generative adversarial network (GAN) based methods have been the state-of-the-art for image super-resolution by utilizing the convolutional neural networks (CNNs) based generator and discriminator networks. However, the CNNs are not able to exploit the global information very effectively in contrast to the transformers, which are the recent breakthrough in deep learning by exploiting the self-attention mechanism. Motivated from the success of transformers in language and vision applications, we propose a SRTransGAN for image super-resolution using transformer based GAN. Specifically, we propose a novel transformer-based encoder-decoder network as a generator to generate 2x images and 4x images. We design the discriminator network using vision transformer which uses the image as sequence of patches and hence useful for binary classification between synthesized and real high-resolution images. The proposed SRTransGAN outperforms the existing methods by 4.38 % on an average of PSNR and SSIM scores. We also analyze the saliency map to understand the learning ability of the proposed method.
PTSR: Patch Translator for Image Super-Resolution
Oct 20, 2023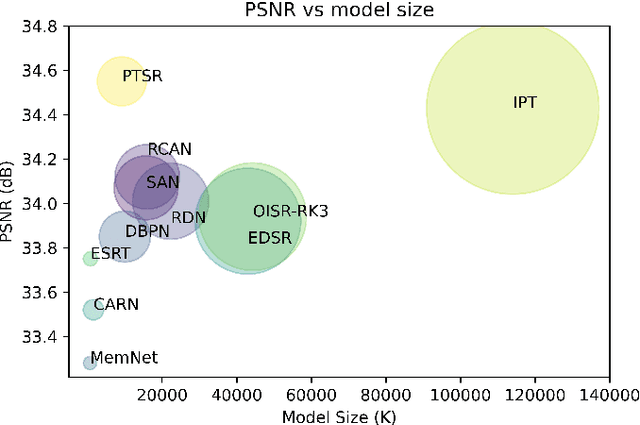
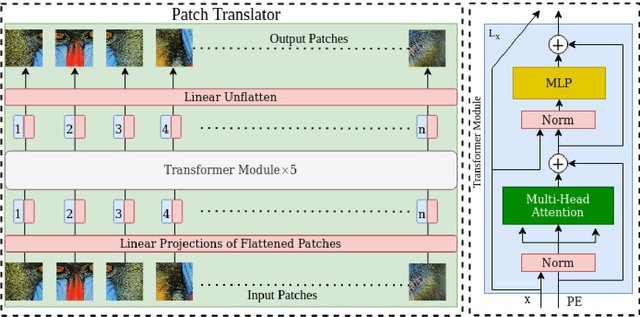
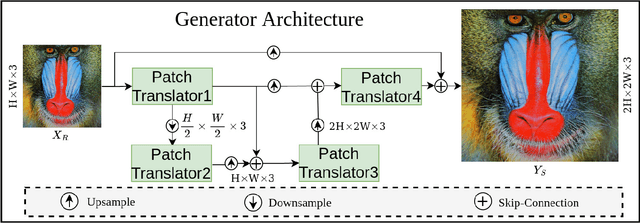
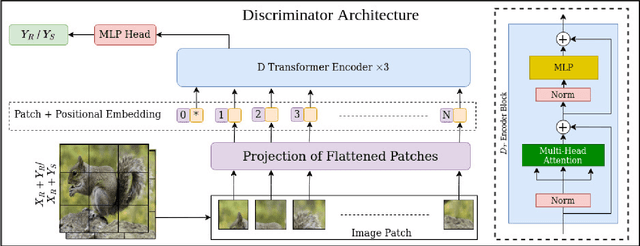
Image super-resolution generation aims to generate a high-resolution image from its low-resolution image. However, more complex neural networks bring high computational costs and memory storage. It is still an active area for offering the promise of overcoming resolution limitations in many applications. In recent years, transformers have made significant progress in computer vision tasks as their robust self-attention mechanism. However, recent works on the transformer for image super-resolution also contain convolution operations. We propose a patch translator for image super-resolution (PTSR) to address this problem. The proposed PTSR is a transformer-based GAN network with no convolution operation. We introduce a novel patch translator module for regenerating the improved patches utilising multi-head attention, which is further utilised by the generator to generate the 2x and 4x super-resolution images. The experiments are performed using benchmark datasets, including DIV2K, Set5, Set14, and BSD100. The results of the proposed model is improved on an average for $4\times$ super-resolution by 21.66% in PNSR score and 11.59% in SSIM score, as compared to the best competitive models. We also analyse the proposed loss and saliency map to show the effectiveness of the proposed method.
Image Conditioned Keyframe-Based Video Summarization Using Object Detection
Sep 11, 2020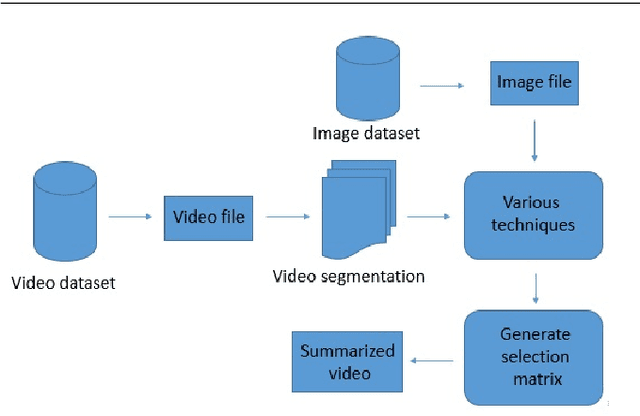
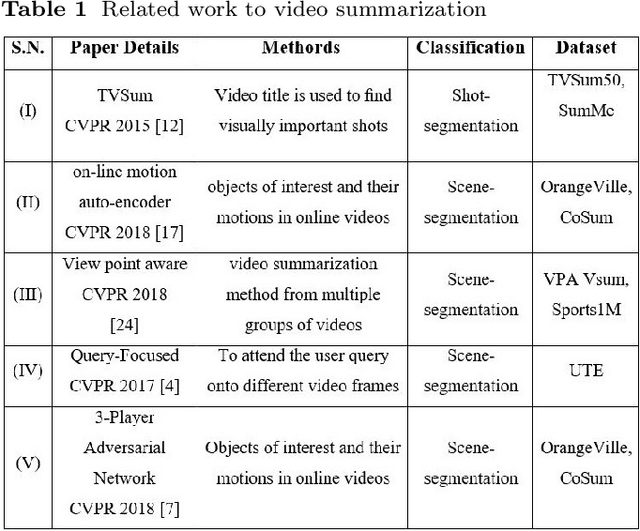
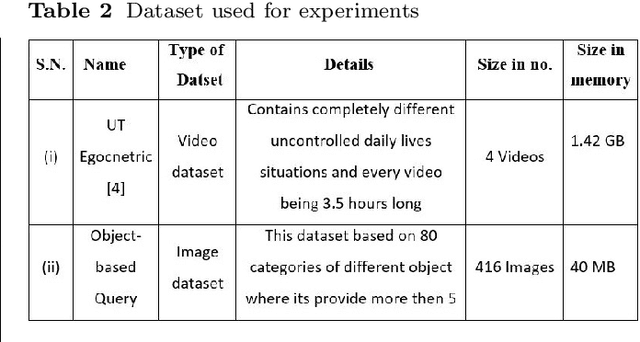
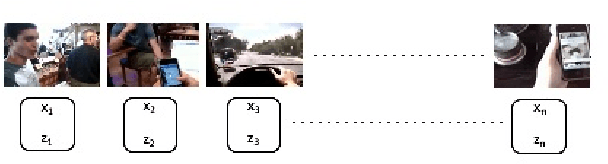
Video summarization plays an important role in selecting keyframe for understanding a video. Traditionally, it aims to find the most representative and diverse contents (or frames) in a video for short summaries. Recently, query-conditioned video summarization has been introduced, which considers user queries to learn more user-oriented summaries and its preference. However, there are obstacles in text queries for user subjectivity and finding similarity between the user query and input frames. In this work, (i) Image is introduced as a query for user preference (ii) a mathematical model is proposed to minimize redundancy based on the loss function & summary variance and (iii) the similarity score between the query image and input video to obtain the summarized video. Furthermore, the Object-based Query Image (OQI) dataset has been introduced, which contains the query images. The proposed method has been validated using UT Egocentric (UTE) dataset. The proposed model successfully resolved the issues of (i) user preference, (ii) recognize important frames and selecting that keyframe in daily life videos, with different illumination conditions. The proposed method achieved 57.06% average F1-Score for UTE dataset and outperforms the existing state-of-theart by 11.01%. The process time is 7.81 times faster than actual time of video Experiments on a recently proposed UTE dataset show the efficiency of the proposed method