 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Switch Networks for Generating Discrete Data and Language
Mar 14, 2019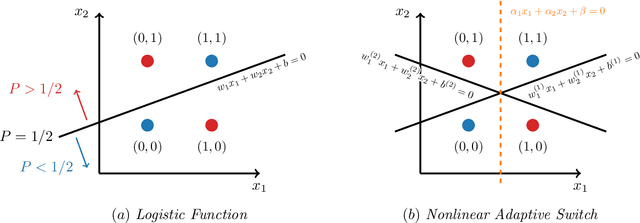

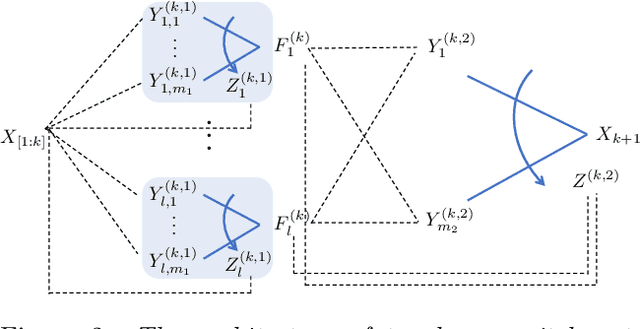
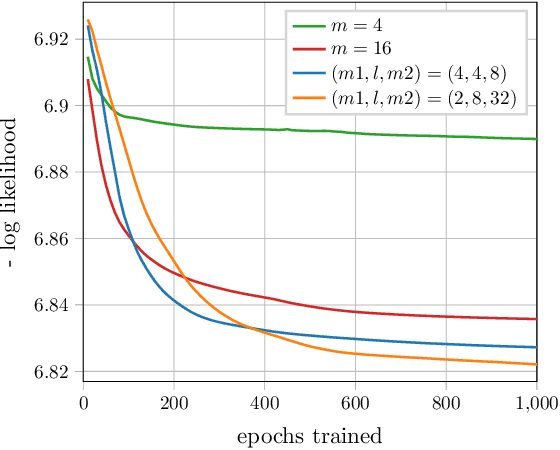
Multilayer switch networks are proposed as artificial generators of high-dimensional discrete data (e.g., binary vectors, categorical data, natural language, network log files, and discrete-valued time series). Unlike deconvolution networks which generate continuous-valued data and which consist of upsampling filters and reverse pooling layers, multilayer switch networks are composed of adaptive switches which model conditional distributions of discrete random variables. An interpretable, statistical framework is introduced for training these nonlinear networks based on a maximum-likelihood objective function. To learn network parameters, stochastic gradient descent is applied to the objective. This direct optimization is stable until convergence, and does not involve back-propagation over separate encoder and decoder networks, or adversarial training of dueling networks. While training remains tractable for moderately sized networks, Markov-chain Monte Carlo (MCMC) approximations of gradients are derived for deep networks which contain latent variables. The statistical framework is evaluated on synthetic data, high-dimensional binary data of handwritten digits, and web-crawled natural language data. Aspects of the model's framework such as interpretability, computational complexity, and generalization ability are discussed.