 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero- and Few-shot Named Entity Recognition and Text Expansion in Medication Prescriptions using ChatGPT
Sep 26, 2024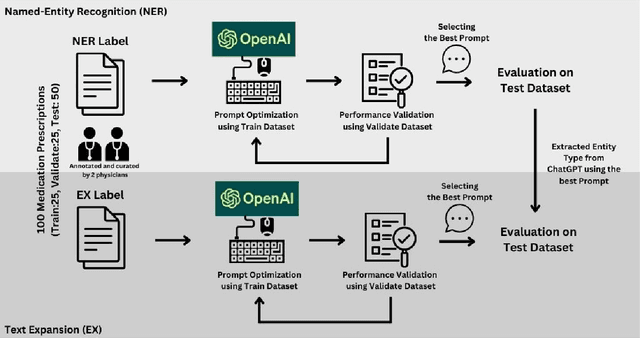

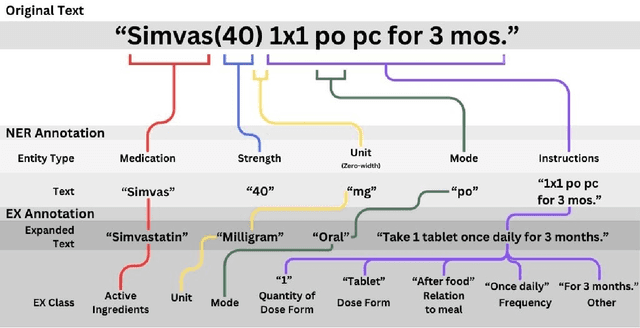
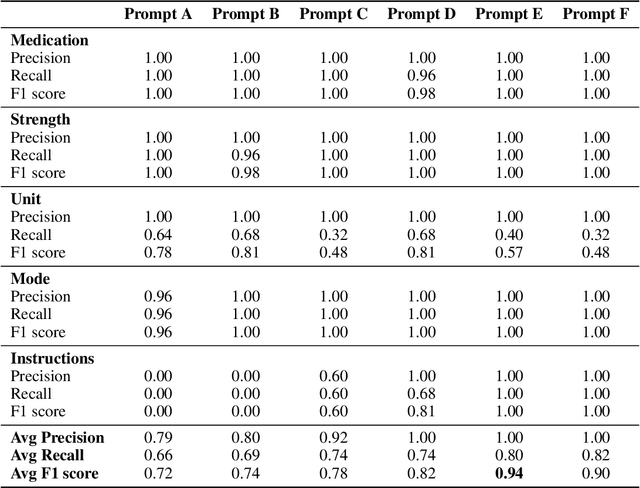
Introduction: Medication prescriptions are often in free text and include a mix of two languages, local brand names, and a wide range of idiosyncratic formats and abbreviations. Large language models (LLMs) have shown promising ability to generate text in response to input prompts. We use ChatGPT 3.5 to automatically structure and expand medication statements in discharge summaries and thus make them easier to interpret for people and machines. Methods: Named-entity Recognition (NER) and Text Expansion (EX) are used in a zero- and few-shot setting with different prompt strategies. 100 medication statements were manually annotated and curated. NER performance was measured by using strict and partial matching. For the task EX, two experts interpreted the results by assessing semantic equivalence between original and expanded statements. The model performance was measured by precision, recall, and F1 score. Results: For NER, the best-performing prompt reached an average F1 score of 0.94 in the test set. For EX, the few-shot prompt showed superior performance among other prompts, with an average F1 score of 0.87. Conclusion: Our study demonstrates good performance for NER and EX tasks in free-text medication statements using ChatGPT. Compared to a zero-shot baseline, a few-shot approach prevented the system from hallucinating, which would be unacceptable when processing safety-relevant medication data.