Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Novel Dataset Towards Extracting Virus-Host Interactions
May 11, 2023
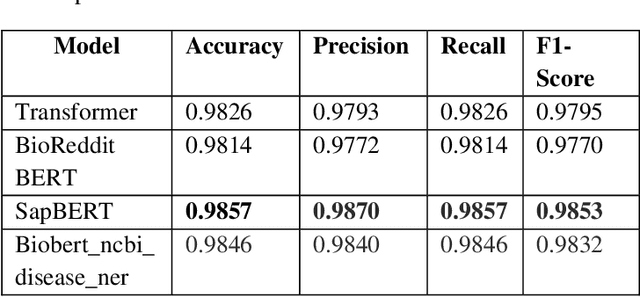


We describe a novel dataset for the automated recognition of named taxonomic and other entities relevant to the association of viruses with their hosts. We further describe some initial results using pre-trained models on the named-entity recognition (NER) task on this novel dataset. We propose that our dataset of manually annotated abstracts now offers a Gold Standard Corpus for training future NER models in the automated extraction of host-pathogen detection methods from scientific publications, and further explain how our work makes first steps towards predicting the important human health-related concept of viral spillover risk automatically from the scientific literature.
* for associated dataset, see
https://1drv.ms/u/s!AjanaqjkM2-ShN9rMT1BqrpAQRpakQ?e=TPkFgh
Via