 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSalesRLAgent: A Reinforcement Learning Approach for Real-Time Sales Conversion Prediction and Optimization
Mar 30, 2025Current approaches to sales conversation analysis and conversion prediction typically rely on Large Language Models (LLMs) combined with basic retrieval augmented generation (RAG). These systems, while capable of answering questions, fail to accurately predict conversion probability or provide strategic guidance in real time. In this paper, we present SalesRLAgent, a novel framework leveraging specialized reinforcement learning to predict conversion probability throughout sales conversations. Unlike systems from Kapa.ai, Mendable, Inkeep, and others that primarily use off-the-shelf LLMs for content generation, our approach treats conversion prediction as a sequential decision problem, training on synthetic data generated using GPT-4O to develop a specialized probability estimation model. Our system incorporates Azure OpenAI embeddings (3072 dimensions), turn-by-turn state tracking, and meta-learning capabilities to understand its own knowledge boundaries. Evaluations demonstrate that SalesRLAgent achieves 96.7% accuracy in conversion prediction, outperforming LLM-only approaches by 34.7% while offering significantly faster inference (85ms vs 3450ms for GPT-4). Furthermore, integration with existing sales platforms shows a 43.2% increase in conversion rates when representatives utilize our system's real-time guidance. SalesRLAgent represents a fundamental shift from content generation to strategic sales intelligence, providing moment-by-moment conversion probability estimation with actionable insights for sales professionals.
ForcePose: A Deep Learning Approach for Force Calculation Based on Action Recognition Using MediaPipe Pose Estimation Combined with Object Detection
Mar 28, 2025

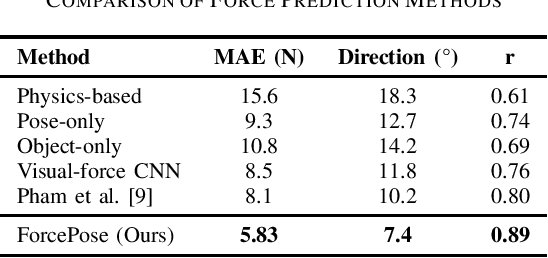

Force estimation in human-object interactions is crucial for various fields like ergonomics, physical therapy, and sports science. Traditional methods depend on specialized equipment such as force plates and sensors, which makes accurate assessments both expensive and restricted to laboratory settings. In this paper, we introduce ForcePose, a novel deep learning framework that estimates applied forces by combining human pose estimation with object detection. Our approach leverages MediaPipe for skeletal tracking and SSD MobileNet for object recognition to create a unified representation of human-object interaction. We've developed a specialized neural network that processes both spatial and temporal features to predict force magnitude and direction without needing any physical sensors. After training on our dataset of 850 annotated videos with corresponding force measurements, our model achieves a mean absolute error of 5.83 N in force magnitude and 7.4 degrees in force direction. When compared to existing computer vision approaches, our method performs 27.5% better while still offering real-time performance on standard computing hardware. ForcePose opens up new possibilities for force analysis in diverse real-world scenarios where traditional measurement tools are impractical or intrusive. This paper discusses our methodology, the dataset creation process, evaluation metrics, and potential applications across rehabilitation, ergonomics assessment, and athletic performance analysis.
DeepRAG: Building a Custom Hindi Embedding Model for Retrieval Augmented Generation from Scratch
Mar 11, 2025In this paper, I present our work on DeepRAG, a specialized embedding model we built specifically for Hindi language in RAG systems. While LLMs have gotten really good at generating text, their performance in retrieval tasks still depends heavily on having quality embeddings - something that's been lacking for Hindi despite being one of the world's most spoken languages. We tackled this by creating embeddings from the ground up rather than just fine-tuning existing models. Our process involved collecting diverse Hindi texts (over 2.7M samples), training a custom SentencePiece tokenizer that actually understands Hindi morphology, designing transformer architecture with Hindi-specific attention mechanisms, and optimizing with contrastive learning. Results were honestly better than I expected - we saw a 23% improvement in retrieval precision compared to the multilingual models everyone's been using. The paper details our methodology, which I think could help others working with low-resource languages where the one-size-fits-all multilingual models fall short. We've also integrated our embeddings with LangChain to build complete Hindi RAG systems, which might be useful for practitioners. While there's still tons more to explore, I believe this work addresses a critical gap for Hindi NLP and demonstrates why language-specific approaches matter.
Continuous Learning Conversational AI: A Personalized Agent Framework via A2C Reinforcement Learning
Feb 18, 2025Creating personalized and adaptable conversational AI remains a key challenge. This paper introduces a Continuous Learning Conversational AI (CLCA) approach, implemented using A2C reinforcement learning, to move beyond static Large Language Models (LLMs). We use simulated sales dialogues, generated by LLMs, to train an A2C agent. This agent learns to optimize conversation strategies for personalization, focusing on engagement and delivering value. Our system architecture integrates reinforcement learning with LLMs for both data creation and response selection. This method offers a practical way to build personalized AI companions that evolve through continuous learning, advancing beyond traditional static LLM techniques.
High-Accuracy ECG Image Interpretation using Parameter-Efficient LoRA Fine-Tuning with Multimodal LLaMA 3.2
Jan 30, 2025Electrocardiogram (ECG) interpretation is a cornerstone of cardiac diagnostics. This paper explores a practical approach to enhance ECG image interpretation using the multimodal LLaMA 3.2 model. We used a parameter-efficient fine-tuning strategy, Low-Rank Adaptation (LoRA), specifically designed to boost the model's ability to understand ECG images and achieve better outcomes across a wide range of cardiac conditions. Our method is tailored for ECG analysis and leverages ECGInstruct, a large-scale instruction dataset with 1 Million samples. This dataset is a rich collection of synthesized ECG images, generated from raw ECG data from trusted open-source repositories like MIMIC-IV ECG and PTB-XL. Each ECG image in ECGInstruct comes with expert-written questions and detailed answers, covering diverse ECG interpretation scenarios, including complex cardiac conditions like Myocardial Infarction and Conduction Disturbances. Our fine-tuning approach efficiently adapts the LLaMA 3.2 model (built upon LLaMA 3) by integrating low-rank adaptation techniques, focusing on efficiency by updating only a small set of parameters, specifically ignoring the `lm_head` and `embed_tokens` layers. This paper details the model setup, our efficient fine-tuning method, and implementation specifics. We provide a thorough evaluation through extensive experiments, demonstrating the effectiveness of our method across various ECG interpretation tasks. The results convincingly show that our parameter-efficient LoRA fine-tuning achieves excellent performance in ECG image interpretation, significantly outperforming baseline models and reaching accuracy comparable to or exceeding traditional CNN-based methods in identifying a wide range of cardiac abnormalities, including over 70 conditions from the PTB-XL dataset.