 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Extreme Learning Machine for Recurrent Beta-basis Function Neural Network Training
Oct 31, 2018

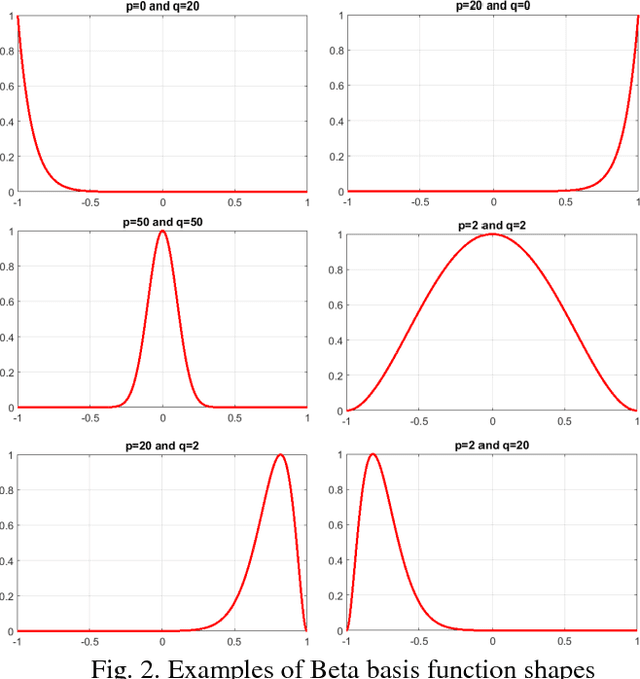

Beta Basis Function Neural Network (BBFNN) is a special kind of kernel basis neural networks. It is a feedforward network typified by the use of beta function as a hidden activation function. Beta is a flexible transfer function representing richer forms than the common existing functions. As in every network, the architecture setting as well as the learning method are two main gauntlets faced by BBFNN. In this paper, new architecture and training algorithm are proposed for the BBFNN. An Extreme Learning Machine (ELM) is used as a training approach of BBFNN with the aim of quickening the training process. The peculiarity of ELM is permitting a certain decrement of the computing time and complexity regarding the already used BBFNN learning algorithms such as backpropagation, OLS, etc. For the architectural design, a recurrent structure is added to the common BBFNN architecture in order to make it more able to deal with complex, non linear and time varying problems. Throughout this paper, the conceived recurrent ELM-trained BBFNN is tested on a number of tasks related to time series prediction, classification and regression. Experimental results show noticeable achievements of the proposed network compared to common feedforward and recurrent networks trained by ELM and using hyperbolic tangent as activation function. These achievements are in terms of accuracy and robustness against data breakdowns such as noise signals.
Genesis of Basic and Multi-Layer Echo State Network Recurrent Autoencoders for Efficient Data Representations
Jun 09, 2018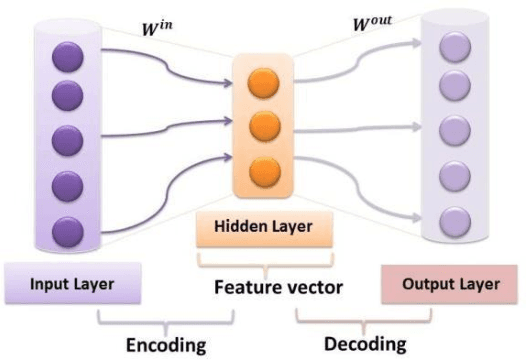

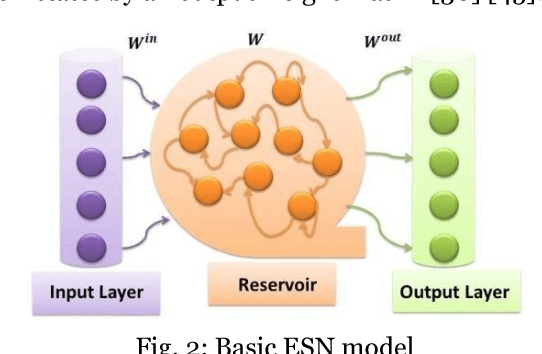

It is a widely accepted fact that data representations intervene noticeably in machine learning tools. The more they are well defined the better the performance results are. Feature extraction-based methods such as autoencoders are conceived for finding more accurate data representations from the original ones. They efficiently perform on a specific task in terms of 1) high accuracy, 2) large short term memory and 3) low execution time. Echo State Network (ESN) is a recent specific kind of Recurrent Neural Network which presents very rich dynamics thanks to its reservoir-based hidden layer. It is widely used in dealing with complex non-linear problems and it has outperformed classical approaches in a number of tasks including regression, classification, etc. In this paper, the noticeable dynamism and the large memory provided by ESN and the strength of Autoencoders in feature extraction are gathered within an ESN Recurrent Autoencoder (ESN-RAE). In order to bring up sturdier alternative to conventional reservoir-based networks, not only single layer basic ESN is used as an autoencoder, but also Multi-Layer ESN (ML-ESN-RAE). The new features, once extracted from ESN's hidden layer, are applied to classification tasks. The classification rates rise considerably compared to those obtained when applying the original data features. An accuracy-based comparison is performed between the proposed recurrent AEs and two variants of an ELM feed-forward AEs (Basic and ML) in both of noise free and noisy environments. The empirical study reveals the main contribution of recurrent connections in improving the classification performance results.
Hierarchical Bi-level Multi-Objective Evolution of Single- and Multi-layer Echo State Network Autoencoders for Data Representations
Jun 09, 2018



Echo State Network (ESN) presents a distinguished kind of recurrent neural networks. It is built upon a sparse, random and large hidden infrastructure called reservoir. ESNs have succeeded in dealing with several non-linear problems such as prediction, classification, etc. Thanks to its rich dynamics, ESN is used as an Autoencoder (AE) to extract features from original data representations. ESN is not only used with its basic single layer form but also with the recently proposed Multi-Layer (ML) architecture. The well setting of ESN (basic and ML) architectures and training parameters is a crucial and hard labor task. Generally, a number of parameters (hidden neurons, sparsity rates, input scaling) is manually altered to achieve minimum learning error. However, this randomly hand crafted task, on one hand, may not guarantee best training results and on the other hand, it can raise the network's complexity. In this paper, a hierarchical bi-level evolutionary optimization is proposed to deal with these issues. The first level includes a multi-objective architecture optimization providing maximum learning accuracy while sustaining the complexity at a reduced standard. Multi-objective Particle Swarm Optimization (MOPSO) is used to optimize ESN structure in a way to provide a trade-off between the network complexity decreasing and the accuracy increasing. A pareto-front of optimal solutions is generated by the end of the MOPSO process. These solutions present the set of candidates that succeeded in providing a compromise between different objectives (learning error and network complexity). At the second level, each of the solutions already found undergo a mono-objective weights optimization to enhance the obtained pareto-front. Empirical results ensure the effectiveness of the evolved ESN recurrent AEs (basic and ML) for noisy and noise free data.