 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimization of Residual Convolutional Neural Network for Electrocardiogram Classification
Dec 11, 2021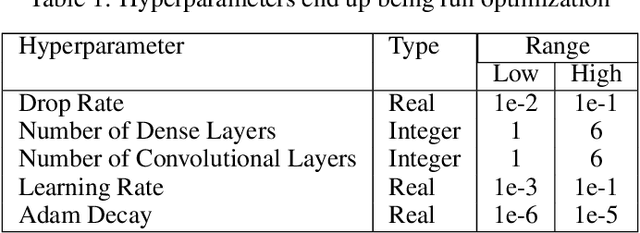
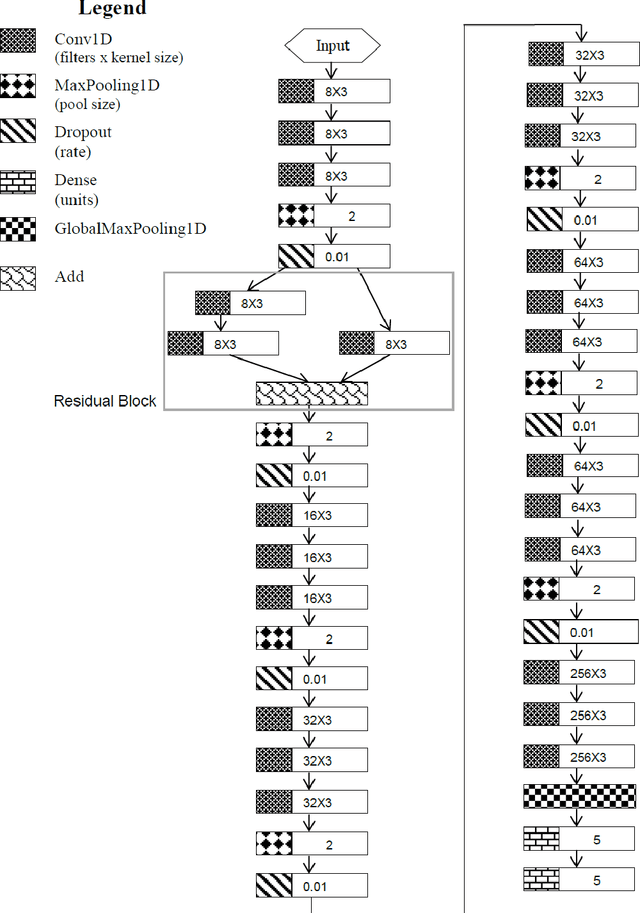
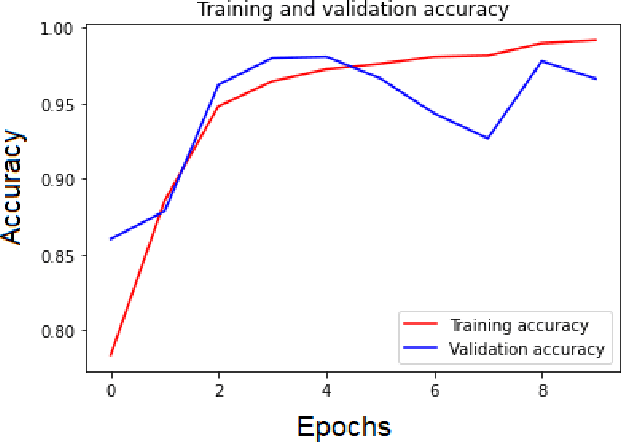

The interpretation of the electrocardiogram (ECG) gives clinical information and helps in the assessing of the heart function. There are distinct ECG patterns associated with a specific class of arrythmia. The convolutional neural network is actually one of the most applied deep learning algorithms in ECG processing. However, with deep learning models there are many more hyperparameters to tune. Selecting an optimum or best hyperparameter for the convolutional neural network algorithm is challenging. Often, we end up tuning the model manually with different possible range of values until a best fit model is obtained. Automatic hyperparameters tuning using Bayesian optimization (BO) and evolutionary algorithms brings a solution to the harbor manual configuration. In this paper, we propose to optimize the Recurrent one Dimensional Convolutional Neural Network model (R-1D-CNN) with two levels. At the first level, a residual convolutional layer and one-dimensional convolutional neural layers are trained to learn patient-specific ECG features over which the multilayer perceptron layers can learn to produce the final class vectors of each input. This level is manual and aims to lower the search space. The second level is automatic and based on proposed algorithm based BO. Our proposed optimized R-1D-CNN architecture is evaluated on two publicly available ECG Datasets. The experimental results display that the proposed algorithm based BO achieves an optimum rate of 99.95\%, while the baseline model achieves 99.70\% for the MIT-BIH database. Moreover, experiments demonstrate that the proposed architecture fine-tuned with BO achieves a higher accuracy than the other proposed architectures. Our architecture achieves a good result compared to previous works and based on different experiments.
Unsupervised Learning in Reservoir Computing for EEG-based Emotion Recognition
Nov 23, 2018



In real-world applications such as emotion recognition from recorded brain activity, data are captured from electrodes over time. These signals constitute a multidimensional time series. In this paper, Echo State Network (ESN), a recurrent neural network with a great success in time series prediction and classification, is optimized with different neural plasticity rules for classification of emotions based on electroencephalogram (EEG) time series. Actually, the neural plasticity rules are a kind of unsupervised learning adapted for the reservoir, i.e. the hidden layer of ESN. More specifically, an investigation of Oja's rule, BCM rule and gaussian intrinsic plasticity rule was carried out in the context of EEG-based emotion recognition. The study, also, includes a comparison of the offline and online training of the ESN. When testing on the well-known affective benchmark "DEAP dataset" which contains EEG signals from 32 subjects, we find that pretraining ESN with gaussian intrinsic plasticity enhanced the classification accuracy and outperformed the results achieved with an ESN pretrained with synaptic plasticity. Four classification problems were conducted in which the system complexity is increased and the discrimination is more challenging, i.e. inter-subject emotion discrimination. Our proposed method achieves higher performance over the state of the art methods.
Genesis of Basic and Multi-Layer Echo State Network Recurrent Autoencoders for Efficient Data Representations
Jun 09, 2018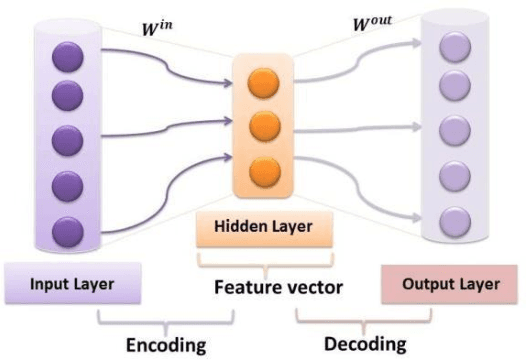

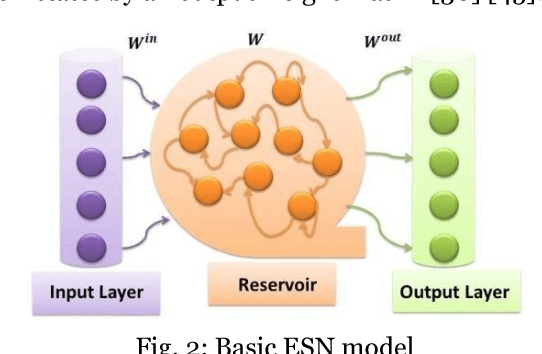

It is a widely accepted fact that data representations intervene noticeably in machine learning tools. The more they are well defined the better the performance results are. Feature extraction-based methods such as autoencoders are conceived for finding more accurate data representations from the original ones. They efficiently perform on a specific task in terms of 1) high accuracy, 2) large short term memory and 3) low execution time. Echo State Network (ESN) is a recent specific kind of Recurrent Neural Network which presents very rich dynamics thanks to its reservoir-based hidden layer. It is widely used in dealing with complex non-linear problems and it has outperformed classical approaches in a number of tasks including regression, classification, etc. In this paper, the noticeable dynamism and the large memory provided by ESN and the strength of Autoencoders in feature extraction are gathered within an ESN Recurrent Autoencoder (ESN-RAE). In order to bring up sturdier alternative to conventional reservoir-based networks, not only single layer basic ESN is used as an autoencoder, but also Multi-Layer ESN (ML-ESN-RAE). The new features, once extracted from ESN's hidden layer, are applied to classification tasks. The classification rates rise considerably compared to those obtained when applying the original data features. An accuracy-based comparison is performed between the proposed recurrent AEs and two variants of an ELM feed-forward AEs (Basic and ML) in both of noise free and noisy environments. The empirical study reveals the main contribution of recurrent connections in improving the classification performance results.
Hierarchical Bi-level Multi-Objective Evolution of Single- and Multi-layer Echo State Network Autoencoders for Data Representations
Jun 09, 2018



Echo State Network (ESN) presents a distinguished kind of recurrent neural networks. It is built upon a sparse, random and large hidden infrastructure called reservoir. ESNs have succeeded in dealing with several non-linear problems such as prediction, classification, etc. Thanks to its rich dynamics, ESN is used as an Autoencoder (AE) to extract features from original data representations. ESN is not only used with its basic single layer form but also with the recently proposed Multi-Layer (ML) architecture. The well setting of ESN (basic and ML) architectures and training parameters is a crucial and hard labor task. Generally, a number of parameters (hidden neurons, sparsity rates, input scaling) is manually altered to achieve minimum learning error. However, this randomly hand crafted task, on one hand, may not guarantee best training results and on the other hand, it can raise the network's complexity. In this paper, a hierarchical bi-level evolutionary optimization is proposed to deal with these issues. The first level includes a multi-objective architecture optimization providing maximum learning accuracy while sustaining the complexity at a reduced standard. Multi-objective Particle Swarm Optimization (MOPSO) is used to optimize ESN structure in a way to provide a trade-off between the network complexity decreasing and the accuracy increasing. A pareto-front of optimal solutions is generated by the end of the MOPSO process. These solutions present the set of candidates that succeeded in providing a compromise between different objectives (learning error and network complexity). At the second level, each of the solutions already found undergo a mono-objective weights optimization to enhance the obtained pareto-front. Empirical results ensure the effectiveness of the evolved ESN recurrent AEs (basic and ML) for noisy and noise free data.