 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMaximum Entropy competes with Maximum Likelihood
Dec 17, 2020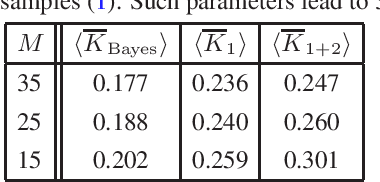


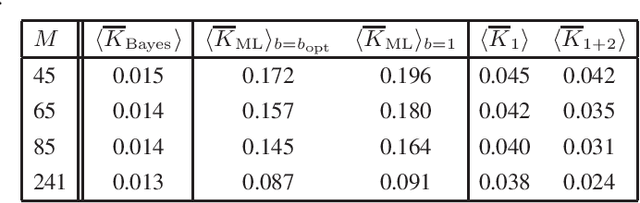
Maximum entropy (MAXENT) method has a large number of applications in theoretical and applied machine learning, since it provides a convenient non-parametric tool for estimating unknown probabilities. The method is a major contribution of statistical physics to probabilistic inference. However, a systematic approach towards its validity limits is currently missing. Here we study MAXENT in a Bayesian decision theory set-up, i.e. assuming that there exists a well-defined prior Dirichlet density for unknown probabilities, and that the average Kullback-Leibler (KL) distance can be employed for deciding on the quality and applicability of various estimators. These allow to evaluate the relevance of various MAXENT constraints, check its general applicability, and compare MAXENT with estimators having various degrees of dependence on the prior, viz. the regularized maximum likelihood (ML) and the Bayesian estimators. We show that MAXENT applies in sparse data regimes, but needs specific types of prior information. In particular, MAXENT can outperform the optimally regularized ML provided that there are prior rank correlations between the estimated random quantity and its probabilities.