 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Neural Network-Based Sign Language Recognition: A Comprehensive Approach Using Transfer Learning with Explainability
Sep 11, 2024To promote inclusion and ensuring effective communication for those who rely on sign language as their main form of communication, sign language recognition (SLR) is crucial. Sign language recognition (SLR) seamlessly incorporates with diverse technology, enhancing accessibility for the deaf community by facilitating their use of digital platforms, video calls, and communication devices. To effectively solve this problem, we suggest a novel solution that uses a deep neural network to fully automate sign language recognition. This methodology integrates sophisticated preprocessing methodologies to optimise the overall performance. The architectures resnet, inception, xception, and vgg are utilised to selectively categorise images of sign language. We prepared a DNN architecture and merged it with the pre-processing architectures. In the post-processing phase, we utilised the SHAP deep explainer, which is based on cooperative game theory, to quantify the influence of specific features on the output of a machine learning model. Bhutanese-Sign-Language (BSL) dataset was used for training and testing the suggested technique. While training on Bhutanese-Sign-Language (BSL) dataset, overall ResNet50 with the DNN model performed better accuracy which is 98.90%. Our model's ability to provide informational clarity was assessed using the SHAP (SHapley Additive exPlanations) method. In part to its considerable robustness and reliability, the proposed methodological approach can be used to develop a fully automated system for sign language recognition.
Real Time Action Recognition from Video Footage
Dec 13, 2021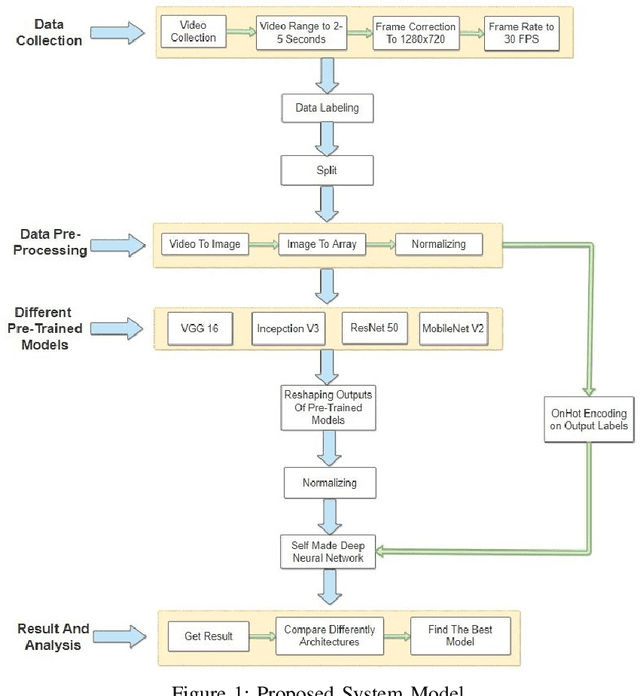
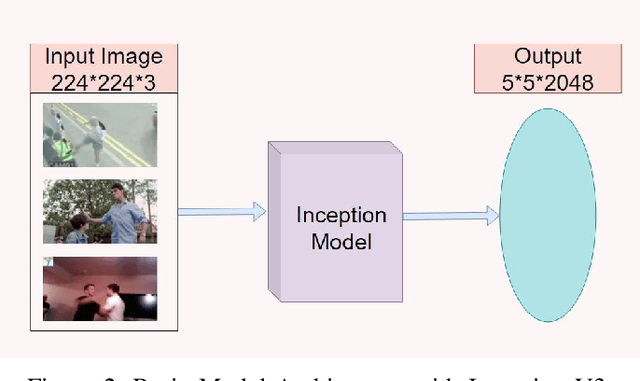

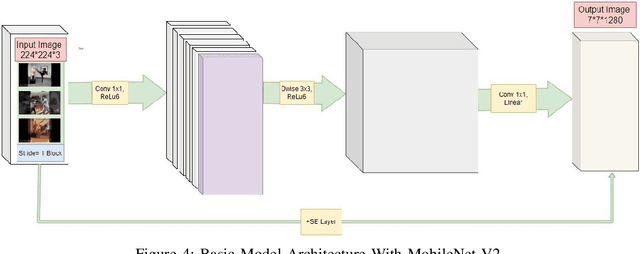
Crime rate is increasing proportionally with the increasing rate of the population. The most prominent approach was to introduce Closed-Circuit Television (CCTV) camera-based surveillance to tackle the issue. Video surveillance cameras have added a new dimension to detect crime. Several research works on autonomous security camera surveillance are currently ongoing, where the fundamental goal is to discover violent activity from video feeds. From the technical viewpoint, this is a challenging problem because analyzing a set of frames, i.e., videos in temporal dimension to detect violence might need careful machine learning model training to reduce false results. This research focuses on this problem by integrating state-of-the-art Deep Learning methods to ensure a robust pipeline for autonomous surveillance for detecting violent activities, e.g., kicking, punching, and slapping. Initially, we designed a dataset of this specific interest, which contains 600 videos (200 for each action). Later, we have utilized existing pre-trained model architectures to extract features, and later used deep learning network for classification. Also, We have classified our models' accuracy, and confusion matrix on different pre-trained architectures like VGG16, InceptionV3, ResNet50, Xception and MobileNet V2 among which VGG16 and MobileNet V2 performed better.