 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWill It Survive? Deciphering the Fate of AI-Generated Code in Open Source
Jan 23, 2026The integration of AI agents as coding assistants into software development has raised questions about the long-term viability of AI agent-generated code. A prevailing hypothesis within the software engineering community suggests this code is "disposable", meaning it is merged quickly but discarded shortly thereafter. If true, organizations risk shifting maintenance burden from generation to post-deployment remediation. We investigate this hypothesis through survival analysis of 201 open-source projects, tracking over 200,000 code units authored by AI agents versus humans. Contrary to the disposable code narrative, agent-authored code survives significantly longer: at the line level, it exhibits a 15.8 percentage-point lower modification rate and 16% lower hazard of modification (HR = 0.842, p < 0.001). However, modification profiles differ. Agent-authored code shows modestly elevated corrective rates (26.3% vs. 23.0%), while human code shows higher adaptive rates. However, the effect sizes are small (Cramér's V = 0.116), and per-agent variation exceeds the agent-human gap. Turning to prediction, textual features can identify modification-prone code (AUC-ROC = 0.671), but predicting when modifications occur remains challenging (Macro F1 = 0.285), suggesting timing depends on external organizational dynamics. The bottleneck for agent-generated code may not be generation quality, but the organizational practices that govern its long-term evolution.
Beyond Synthetic Benchmarks: Evaluating LLM Performance on Real-World Class-Level Code Generation
Oct 30, 2025Large language models (LLMs) have advanced code generation at the function level, yet their ability to produce correct class-level implementations in authentic software projects remains poorly understood. This work introduces a novel benchmark derived from open-source repositories, comprising real-world classes divided into seen and unseen partitions to evaluate generalization under practical conditions. The evaluation examines multiple LLMs under varied input specifications, retrieval-augmented configurations, and documentation completeness levels. Results reveal a stark performance disparity: LLMs achieve 84% to 89% correctness on established synthetic benchmarks but only 25% to 34% on real-world class tasks, with negligible differences between familiar and novel codebases. Comprehensive docstrings yield modest gains of 1% to 3% in functional accuracy, though statistical significance is rare. Retrieval-augmented generation proves most effective with partial documentation, improving correctness by 4% to 7% by supplying concrete implementation patterns absent from specifications. Error profiling identifies AttributeError, TypeError, and AssertionError as dominant failure modes (84% of cases), with synthetic tests overemphasizing assertion issues and real-world scenarios highlighting type and attribute mismatches. Retrieval augmentation reduces logical flaws but can introduce dependency conflicts. The benchmark and analysis expose critical limitations in current LLM capabilities for class-level engineering, offering actionable insights for enhancing context modelling, documentation strategies, and retrieval integration in production code assistance tools.
A Large-scale Class-level Benchmark Dataset for Code Generation with LLMs
Apr 22, 2025



Recent advancements in large language models (LLMs) have demonstrated promising capabilities in code generation tasks. However, most existing benchmarks focus on isolated functions and fail to capture the complexity of real-world, class-level software structures. To address this gap, we introduce a large-scale, Python class-level dataset curated from $13{,}174$ real-world open-source projects. The dataset contains over 842,000 class skeletons, each including class and method signatures, along with associated docstrings when available. We preserve structural and contextual dependencies critical to realistic software development scenarios and enrich the dataset with static code metrics to support downstream analysis. To evaluate the usefulness of this dataset, we use extracted class skeletons as prompts for GPT-4 to generate full class implementations. Results show that the LLM-generated classes exhibit strong lexical and structural similarity to human-written counterparts, with average ROUGE@L, BLEU, and TSED scores of 0.80, 0.59, and 0.73, respectively. These findings confirm that well-structured prompts derived from real-world class skeletons significantly enhance LLM performance in class-level code generation. This dataset offers a valuable resource for benchmarking, training, and improving LLMs in realistic software engineering contexts.
Automatic Detection of LLM-generated Code: A Case Study of Claude 3 Haiku
Sep 02, 2024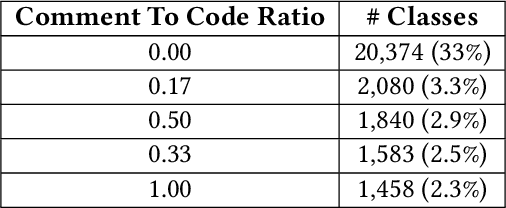
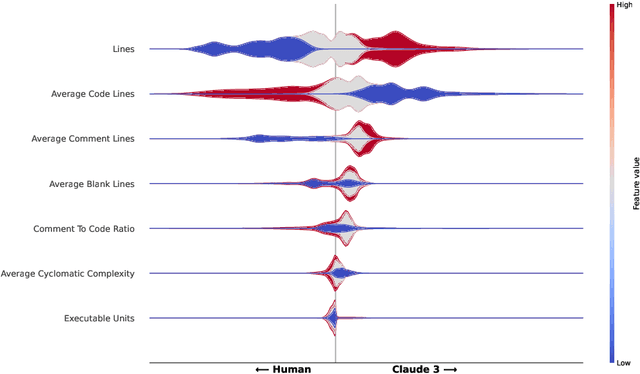
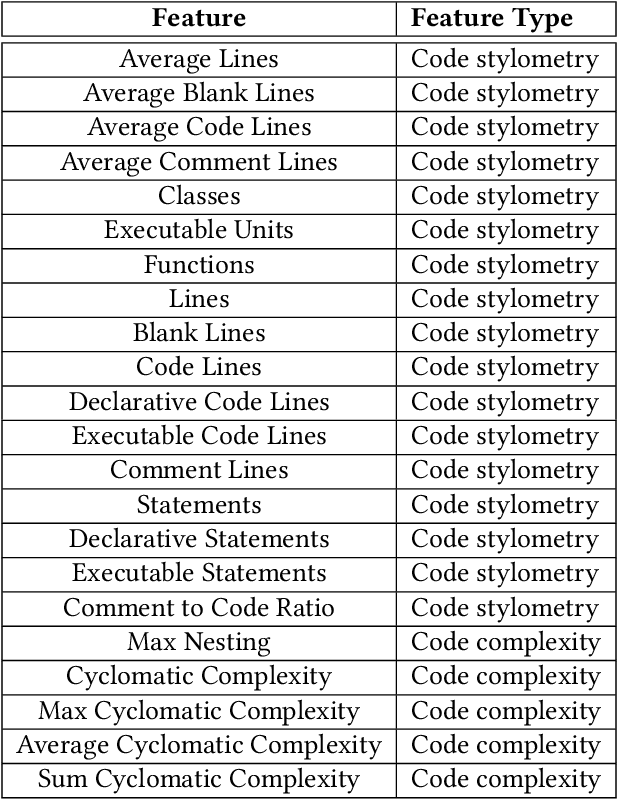
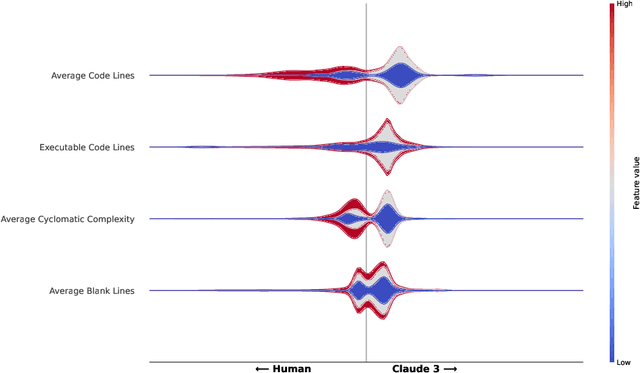
Using Large Language Models (LLMs) has gained popularity among software developers for generating source code. However, the use of LLM-generated code can introduce risks of adding suboptimal, defective, and vulnerable code. This makes it necessary to devise methods for the accurate detection of LLM-generated code. Toward this goal, we perform a case study of Claude 3 Haiku (or Claude 3 for brevity) on CodeSearchNet dataset. We divide our analyses into two parts: function-level and class-level. We extract 22 software metric features, such as Code Lines and Cyclomatic Complexity, for each level of granularity. We then analyze code snippets generated by Claude 3 and their human-authored counterparts using the extracted features to understand how unique the code generated by Claude 3 is. In the following step, we use the unique characteristics of Claude 3-generated code to build Machine Learning (ML) models and identify which features of the code snippets make them more detectable by ML models. Our results indicate that Claude 3 tends to generate longer functions, but shorter classes than humans, and this characteristic can be used to detect Claude 3-generated code with ML models with 82% and 66% accuracies for function-level and class-level snippets, respectively.
On the Variability of AI-based Software Systems Due to Environment Configurations
Aug 05, 2024



[Context] Nowadays, many software systems include Artificial Intelligence (AI) components and changes in the development environment have been known to induce variability in an AI-based system. [Objective] However, how an environment configuration impacts the variability of these systems is yet to be explored. Understanding and quantifying the degree of variability due to such configurations can help practitioners decide the best environment configuration for the most stable AI products. [Method] To achieve this goal, we performed experiments with eight different combinations of three key environment variables (operating system, Python version, and CPU architecture) on 30 open-source AI-based systems using the Travis CI platform. We evaluate variability using three metrics: the output of an AI component like an ML model (performance), the time required to build and run a system (processing time), and the cost associated with building and running a system (expense). [Results] Our results indicate that variability exists in all three metrics; however, it is observed more frequently with respect to processing time and expense than performance. For example, between Linux and MacOS, variabilities are observed in 23%, 96.67%, and 100% of the studied projects in performance, processing time, and expense, respectively. [Conclusion] Our findings underscore the importance of identifying the optimal combination of configuration settings to mitigate performance drops and reduce retraining time and cost before deploying an AI-based system.