 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dual-Tier Adaptive One-Class Classification IDS for Emerging Cyberthreats
Mar 17, 2024In today's digital age, our dependence on IoT (Internet of Things) and IIoT (Industrial IoT) systems has grown immensely, which facilitates sensitive activities such as banking transactions and personal, enterprise data, and legal document exchanges. Cyberattackers consistently exploit weak security measures and tools. The Network Intrusion Detection System (IDS) acts as a primary tool against such cyber threats. However, machine learning-based IDSs, when trained on specific attack patterns, often misclassify new emerging cyberattacks. Further, the limited availability of attack instances for training a supervised learner and the ever-evolving nature of cyber threats further complicate the matter. This emphasizes the need for an adaptable IDS framework capable of recognizing and learning from unfamiliar/unseen attacks over time. In this research, we propose a one-class classification-driven IDS system structured on two tiers. The first tier distinguishes between normal activities and attacks/threats, while the second tier determines if the detected attack is known or unknown. Within this second tier, we also embed a multi-classification mechanism coupled with a clustering algorithm. This model not only identifies unseen attacks but also uses them for retraining them by clustering unseen attacks. This enables our model to be future-proofed, capable of evolving with emerging threat patterns. Leveraging one-class classifiers (OCC) at the first level, our approach bypasses the need for attack samples, addressing data imbalance and zero-day attack concerns and OCC at the second level can effectively separate unknown attacks from the known attacks. Our methodology and evaluations indicate that the presented framework exhibits promising potential for real-world deployments.
Hierarchical Classification for Intrusion Detection System: Effective Design and Empirical Analysis
Mar 17, 2024



With the increased use of network technologies like Internet of Things (IoT) in many real-world applications, new types of cyberattacks have been emerging. To safeguard critical infrastructures from these emerging threats, it is crucial to deploy an Intrusion Detection System (IDS) that can detect different types of attacks accurately while minimizing false alarms. Machine learning approaches have been used extensively in IDS and they are mainly using flat multi-class classification to differentiate normal traffic and different types of attacks. Though cyberattack types exhibit a hierarchical structure where similar granular attack subtypes can be grouped into more high-level attack types, hierarchical classification approach has not been explored well. In this paper, we investigate the effectiveness of hierarchical classification approach in IDS. We use a three-level hierarchical classification model to classify various network attacks, where the first level classifies benign or attack, the second level classifies coarse high-level attack types, and the third level classifies a granular level attack types. Our empirical results of using 10 different classification algorithms in 10 different datasets show that there is no significant difference in terms of overall classification performance (i.e., detecting normal and different types of attack correctly) of hierarchical and flat classification approaches. However, flat classification approach misclassify attacks as normal whereas hierarchical approach misclassify one type of attack as another attack type. In other words, the hierarchical classification approach significantly minimises attacks from misclassified as normal traffic, which is more important in critical systems.
usfAD Based Effective Unknown Attack Detection Focused IDS Framework
Mar 17, 2024The rapid expansion of varied network systems, including the Internet of Things (IoT) and Industrial Internet of Things (IIoT), has led to an increasing range of cyber threats. Ensuring robust protection against these threats necessitates the implementation of an effective Intrusion Detection System (IDS). For more than a decade, researchers have delved into supervised machine learning techniques to develop IDS to classify normal and attack traffic. However, building effective IDS models using supervised learning requires a substantial number of benign and attack samples. To collect a sufficient number of attack samples from real-life scenarios is not possible since cyber attacks occur occasionally. Further, IDS trained and tested on known datasets fails in detecting zero-day or unknown attacks due to the swift evolution of attack patterns. To address this challenge, we put forth two strategies for semi-supervised learning based IDS where training samples of attacks are not required: 1) training a supervised machine learning model using randomly and uniformly dispersed synthetic attack samples; 2) building a One Class Classification (OCC) model that is trained exclusively on benign network traffic. We have implemented both approaches and compared their performances using 10 recent benchmark IDS datasets. Our findings demonstrate that the OCC model based on the state-of-art anomaly detection technique called usfAD significantly outperforms conventional supervised classification and other OCC based techniques when trained and tested considering real-life scenarios, particularly to detect previously unseen attacks.
Fake or Genuine? Contextualised Text Representation for Fake Review Detection
Dec 29, 2021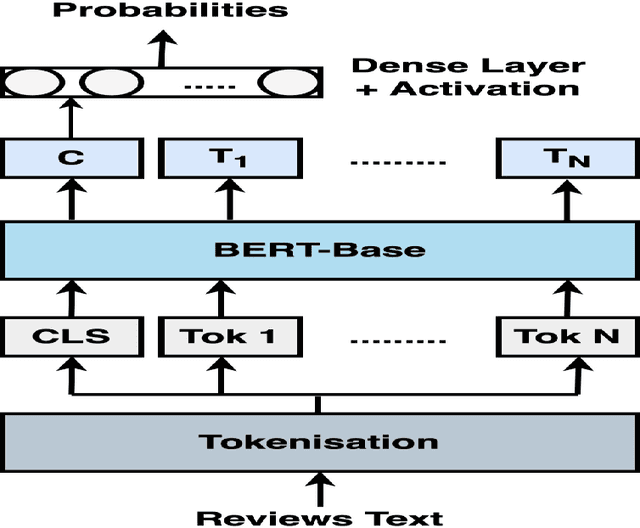

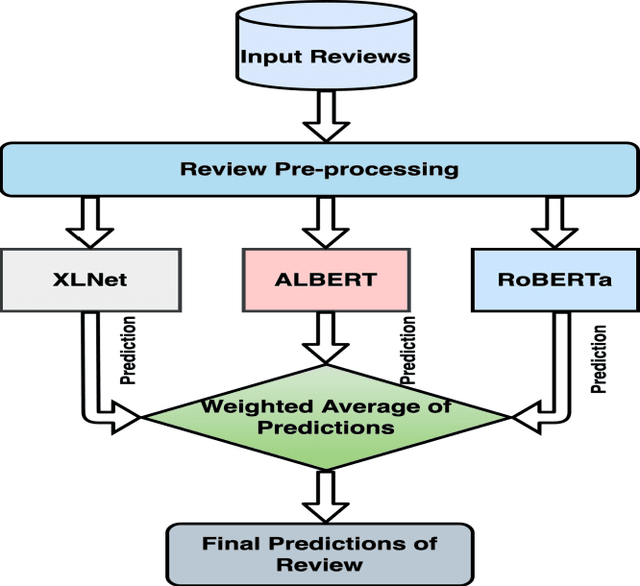
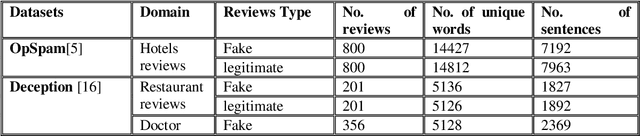
Online reviews have a significant influence on customers' purchasing decisions for any products or services. However, fake reviews can mislead both consumers and companies. Several models have been developed to detect fake reviews using machine learning approaches. Many of these models have some limitations resulting in low accuracy in distinguishing between fake and genuine reviews. These models focused only on linguistic features to detect fake reviews and failed to capture the semantic meaning of the reviews. To deal with this, this paper proposes a new ensemble model that employs transformer architecture to discover the hidden patterns in a sequence of fake reviews and detect them precisely. The proposed approach combines three transformer models to improve the robustness of fake and genuine behaviour profiling and modelling to detect fake reviews. The experimental results using semi-real benchmark datasets showed the superiority of the proposed model over state-of-the-art models.