 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Text Segmentation via Kernel Change-Point Detection on Sentence Embeddings
Jan 26, 2026Unsupervised text segmentation is crucial because boundary labels are expensive, subjective, and often fail to transfer across domains and granularity choices. We propose Embed-KCPD, a training-free method that represents sentences as embedding vectors and estimates boundaries by minimizing a penalized KCPD objective. Beyond the algorithmic instantiation, we develop, to our knowledge, the first dependence-aware theory for KCPD under $m$-dependent sequences, a finite-memory abstraction of short-range dependence common in language. We prove an oracle inequality for the population penalized risk and a localization guarantee showing that each true change point is recovered within a window that is small relative to segment length. To connect theory to practice, we introduce an LLM-based simulation framework that generates synthetic documents with controlled finite-memory dependence and known boundaries, validating the predicted scaling behavior. Across standard segmentation benchmarks, Embed-KCPD often outperforms strong unsupervised baselines. A case study on Taylor Swift's tweets illustrates that Embed-KCPD combines strong theoretical guarantees, simulated reliability, and practical effectiveness for text segmentation.
Dynamics of "Spontaneous" Topic Changes in Next Token Prediction with Self-Attention
Jan 10, 2025
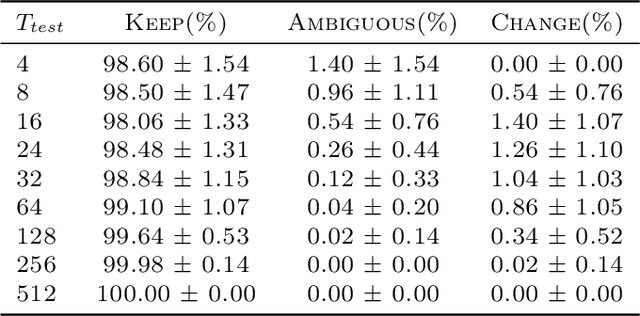
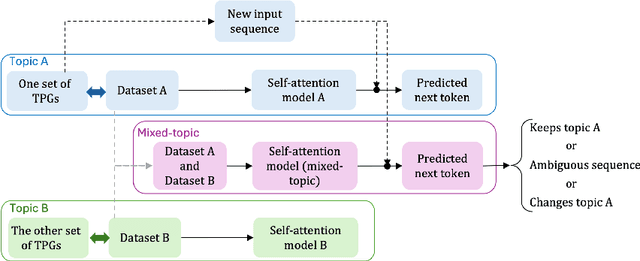
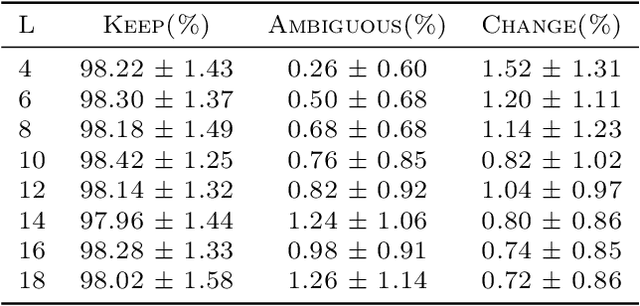
Human cognition can spontaneously shift conversation topics, often triggered by emotional or contextual signals. In contrast, self-attention-based language models depend on structured statistical cues from input tokens for next-token prediction, lacking this spontaneity. Motivated by this distinction, we investigate the factors that influence the next-token prediction to change the topic of the input sequence. We define concepts of topic continuity, ambiguous sequences, and change of topic, based on defining a topic as a set of token priority graphs (TPGs). Using a simplified single-layer self-attention architecture, we derive analytical characterizations of topic changes. Specifically, we demonstrate that (1) the model maintains the priority order of tokens related to the input topic, (2) a topic change occurs only if lower-priority tokens outnumber all higher-priority tokens of the input topic, and (3) unlike human cognition, longer context lengths and overlapping topics reduce the likelihood of spontaneous redirection. These insights highlight differences between human cognition and self-attention-based models in navigating topic changes and underscore the challenges in designing conversational AI capable of handling "spontaneous" conversations more naturally. To our knowledge, this is the first work to address these questions in such close relation to human conversation and thought.