 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSmart Sampling: Self-Attention and Bootstrapping for Improved Ensembled Q-Learning
May 14, 2024



We present a novel method aimed at enhancing the sample efficiency of ensemble Q learning. Our proposed approach integrates multi-head self-attention into the ensembled Q networks while bootstrapping the state-action pairs ingested by the ensemble. This not only results in performance improvements over the original REDQ (Chen et al. 2021) and its variant DroQ (Hi-raoka et al. 2022), thereby enhancing Q predictions, but also effectively reduces both the average normalized bias and standard deviation of normalized bias within Q-function ensembles. Importantly, our method also performs well even in scenarios with a low update-to-data (UTD) ratio. Notably, the implementation of our proposed method is straightforward, requiring minimal modifications to the base model.
Enhanced Multimodal Content Moderation of Children's Videos using Audiovisual Fusion
May 09, 2024



Due to the rise in video content creation targeted towards children, there is a need for robust content moderation schemes for video hosting platforms. A video that is visually benign may include audio content that is inappropriate for young children while being impossible to detect with a unimodal content moderation system. Popular video hosting platforms for children such as YouTube Kids still publish videos which contain audio content that is not conducive to a child's healthy behavioral and physical development. A robust classification of malicious videos requires audio representations in addition to video features. However, recent content moderation approaches rarely employ multimodal architectures that explicitly consider non-speech audio cues. To address this, we present an efficient adaptation of CLIP (Contrastive Language-Image Pre-training) that can leverage contextual audio cues for enhanced content moderation. We incorporate 1) the audio modality and 2) prompt learning, while keeping the backbone modules of each modality frozen. We conduct our experiments on a multimodal version of the MOB (Malicious or Benign) dataset in supervised and few-shot settings.
Malicious or Benign? Towards Effective Content Moderation for Children's Videos
May 24, 2023

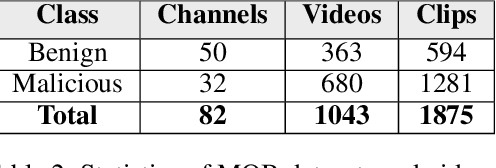

Online video platforms receive hundreds of hours of uploads every minute, making manual content moderation impossible. Unfortunately, the most vulnerable consumers of malicious video content are children from ages 1-5 whose attention is easily captured by bursts of color and sound. Scammers attempting to monetize their content may craft malicious children's videos that are superficially similar to educational videos, but include scary and disgusting characters, violent motions, loud music, and disturbing noises. Prominent video hosting platforms like YouTube have taken measures to mitigate malicious content on their platform, but these videos often go undetected by current content moderation tools that are focused on removing pornographic or copyrighted content. This paper introduces our toolkit Malicious or Benign for promoting research on automated content moderation of children's videos. We present 1) a customizable annotation tool for videos, 2) a new dataset with difficult to detect test cases of malicious content and 3) a benchmark suite of state-of-the-art video classification models.
* 10 pages, 7 figures, The 36th International FLAIRS Conference
Transformer-based Value Function Decomposition for Cooperative Multi-agent Reinforcement Learning in StarCraft
Aug 15, 2022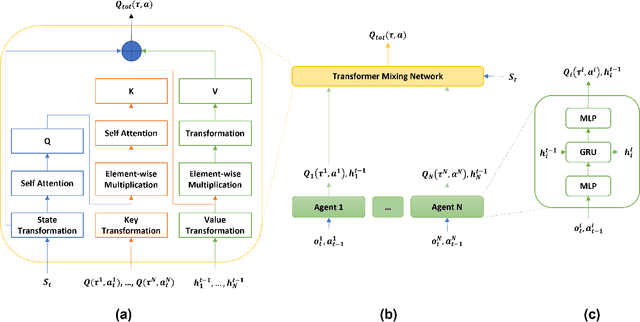
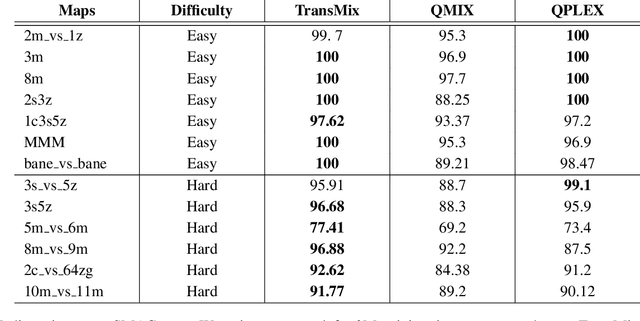
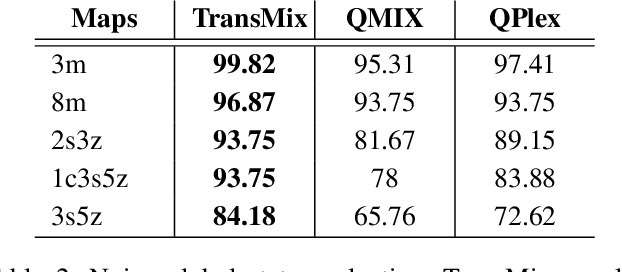
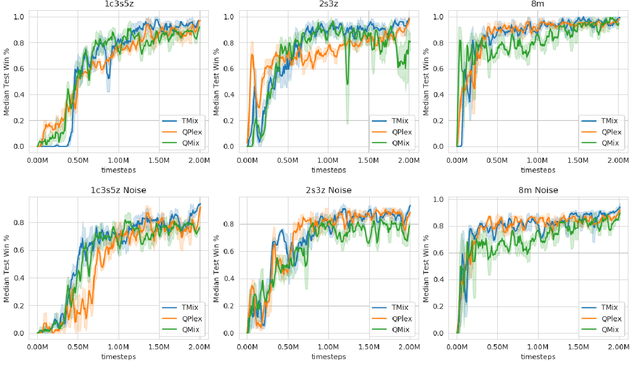
The StarCraft II Multi-Agent Challenge (SMAC) was created to be a challenging benchmark problem for cooperative multi-agent reinforcement learning (MARL). SMAC focuses exclusively on the problem of StarCraft micromanagement and assumes that each unit is controlled individually by a learning agent that acts independently and only possesses local information; centralized training is assumed to occur with decentralized execution (CTDE). To perform well in SMAC, MARL algorithms must handle the dual problems of multi-agent credit assignment and joint action evaluation. This paper introduces a new architecture TransMix, a transformer-based joint action-value mixing network which we show to be efficient and scalable as compared to the other state-of-the-art cooperative MARL solutions. TransMix leverages the ability of transformers to learn a richer mixing function for combining the agents' individual value functions. It achieves comparable performance to previous work on easy SMAC scenarios and outperforms other techniques on hard scenarios, as well as scenarios that are corrupted with Gaussian noise to simulate fog of war.
Leveraging Transformers for StarCraft Macromanagement Prediction
Oct 11, 2021
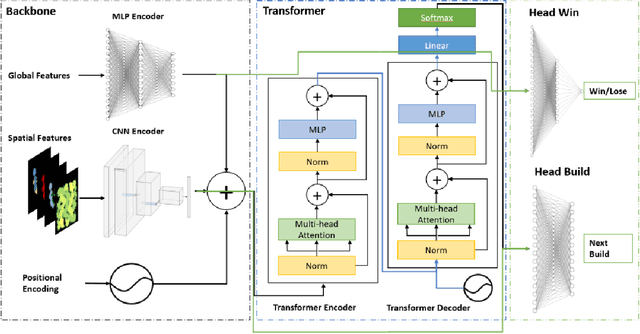
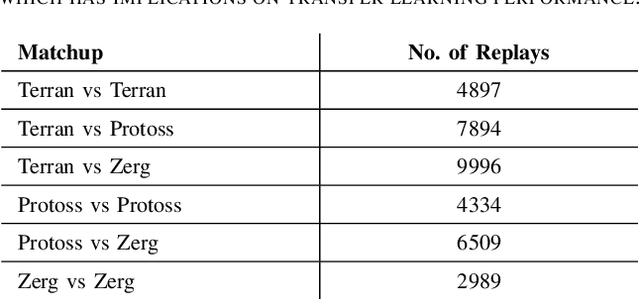
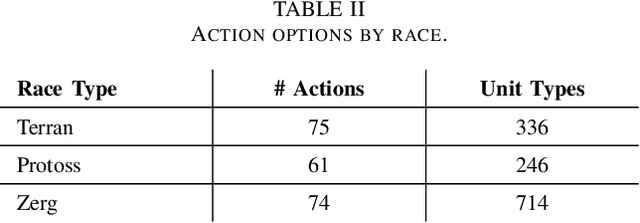
Inspired by the recent success of transformers in natural language processing and computer vision applications, we introduce a transformer-based neural architecture for two key StarCraft II (SC2) macromanagement tasks: global state and build order prediction. Unlike recurrent neural networks which suffer from a recency bias, transformers are able to capture patterns across very long time horizons, making them well suited for full game analysis. Our model utilizes the MSC (Macromanagement in StarCraft II) dataset and improves on the top performing gated recurrent unit (GRU) architecture in predicting global state and build order as measured by mean accuracy over multiple time horizons. We present ablation studies on our proposed architecture that support our design decisions. One key advantage of transformers is their ability to generalize well, and we demonstrate that our model achieves an even better accuracy when used in a transfer learning setting in which models trained on games with one racial matchup (e.g., Terran vs. Protoss) are transferred to a different one. We believe that transformers' ability to model long games, potential for parallelization, and generalization performance make them an excellent choice for StarCraft agents.