 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCursive Scene Text Analysis by Deep Convolutional Linear Pyramids
Sep 27, 2018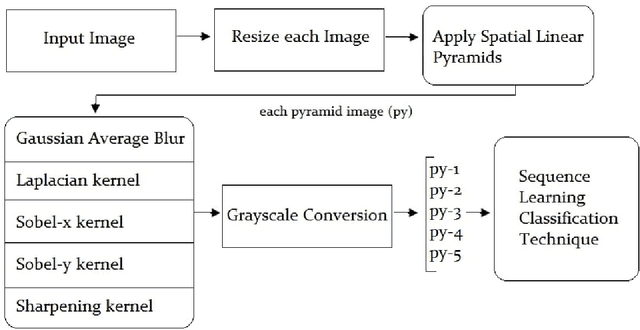


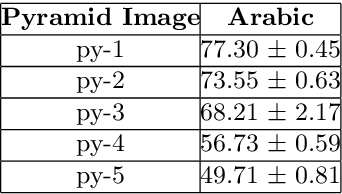
The camera captured images have various aspects to investigate. Generally, the emphasis of research depends on the interesting regions. Sometimes the focus could be on color segmentation, object detection or scene text analysis. The image analysis, visibility and layout analysis are the tasks easier for humans as suggested by behavioral trait of humans, but in contrast when these same tasks are supposed to perform by machines then it seems to be challenging. The learning machines always learn from the properties associated to provided samples. The numerous approaches are designed in recent years for scene text extraction and recognition and the efforts are underway to improve the accuracy. The convolutional approach provided reasonable results on non-cursive text analysis appeared in natural images. The work presented in this manuscript exploited the strength of linear pyramids by considering each pyramid as a feature of the provided sample. Each pyramid image process through various empirically selected kernels. The performance was investigated by considering Arabic text on each image pyramid of EASTR-42k dataset. The error rate of 0.17% was reported on Arabic scene text recognition.
Handwritten Urdu Character Recognition using 1-Dimensional BLSTM Classifier
May 15, 2017
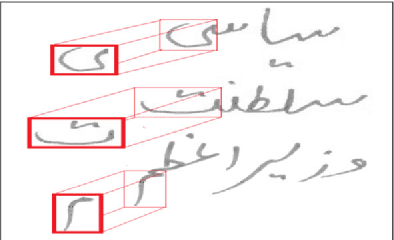
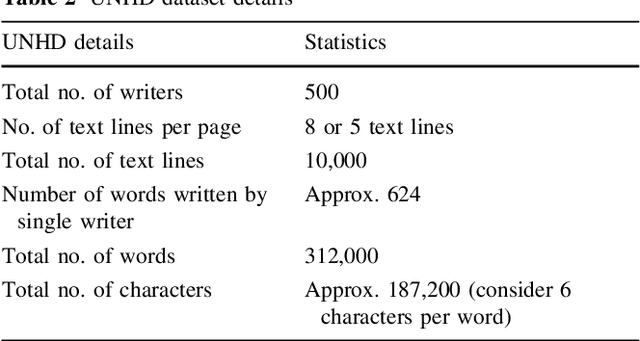
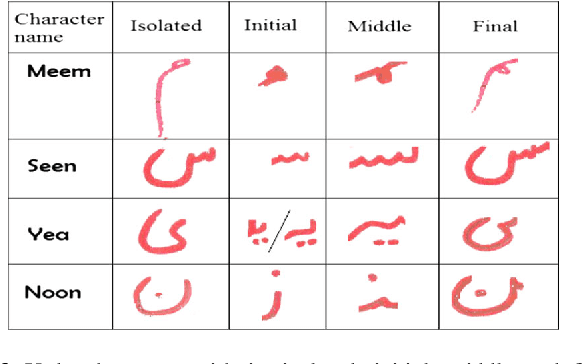
The recognition of cursive script is regarded as a subtle task in optical character recognition due to its varied representation. Every cursive script has different nature and associated challenges. As Urdu is one of cursive language that is derived from Arabic script, thats why it nearly shares the same challenges and difficulties even more harder. We can categorized Urdu and Arabic language on basis of its script they use. Urdu is mostly written in Nastaliq style whereas, Arabic follows Naskh style of writing. This paper presents new and comprehensive Urdu handwritten offline database name Urdu-Nastaliq Handwritten Dataset (UNHD). Currently, there is no standard and comprehensive Urdu handwritten dataset available publicly for researchers. The acquired dataset covers commonly used ligatures that were written by 500 writers with their natural handwriting on A4 size paper. We performed experiments using recurrent neural networks and reported a significant accuracy for handwritten Urdu character recognition.
Deep Learning for Medical Image Processing: Overview, Challenges and Future
Apr 22, 2017
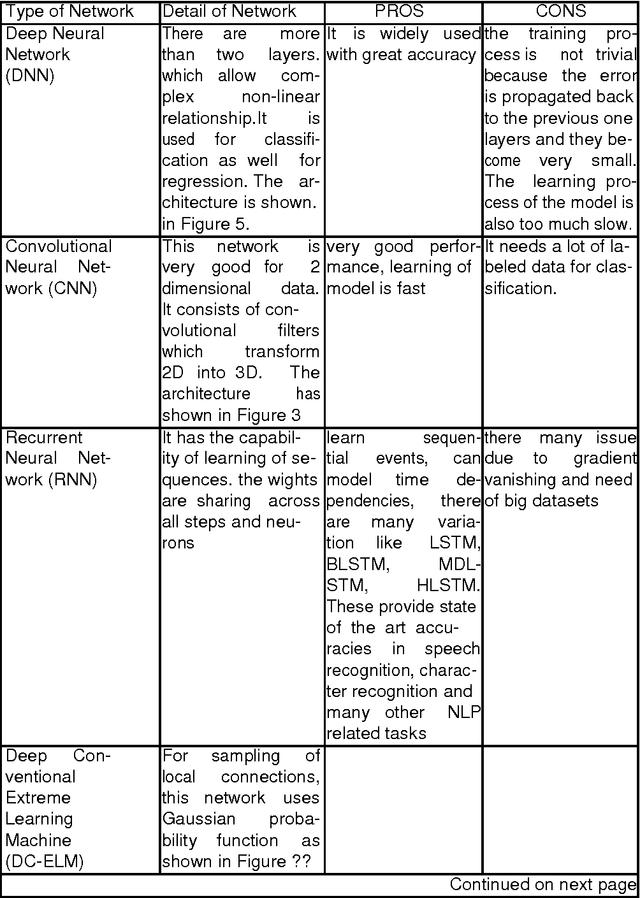

Healthcare sector is totally different from other industry. It is on high priority sector and people expect highest level of care and services regardless of cost. It did not achieve social expectation even though it consume huge percentage of budget. Mostly the interpretations of medical data is being done by medical expert. In terms of image interpretation by human expert, it is quite limited due to its subjectivity, the complexity of the image, extensive variations exist across different interpreters, and fatigue. After the success of deep learning in other real world application, it is also providing exciting solutions with good accuracy for medical imaging and is seen as a key method for future applications in health secotr. In this chapter, we discussed state of the art deep learning architecture and its optimization used for medical image segmentation and classification. In the last section, we have discussed the challenges deep learning based methods for medical imaging and open research issue.
Deep Learning based Isolated Arabic Scene Character Recognition
Apr 22, 2017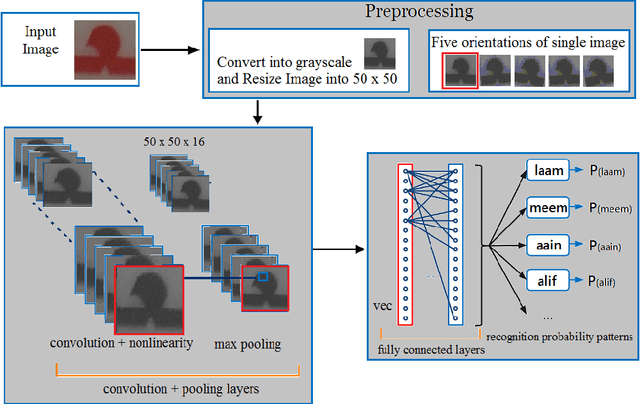
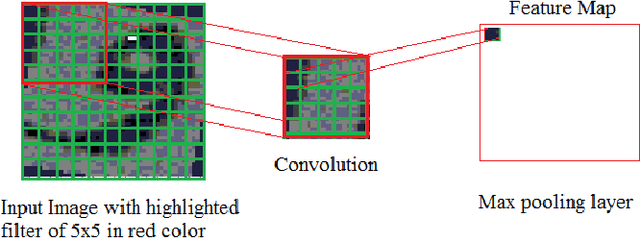


The technological advancement and sophistication in cameras and gadgets prompt researchers to have focus on image analysis and text understanding. The deep learning techniques demonstrated well to assess the potential for classifying text from natural scene images as reported in recent years. There are variety of deep learning approaches that prospects the detection and recognition of text, effectively from images. In this work, we presented Arabic scene text recognition using Convolutional Neural Networks (ConvNets) as a deep learning classifier. As the scene text data is slanted and skewed, thus to deal with maximum variations, we employ five orientations with respect to single occurrence of a character. The training is formulated by keeping filter size 3 x 3 and 5 x 5 with stride value as 1 and 2. During text classification phase, we trained network with distinct learning rates. Our approach reported encouraging results on recognition of Arabic characters from segmented Arabic scene images.