 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandwritten Urdu Character Recognition using 1-Dimensional BLSTM Classifier
Paper and Code
May 15, 2017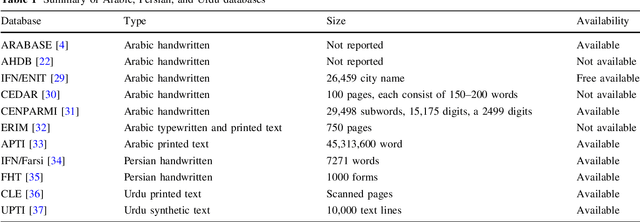
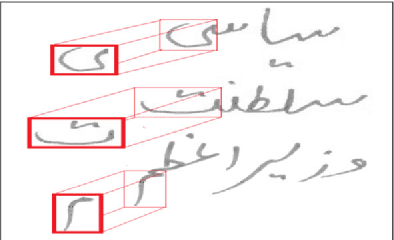
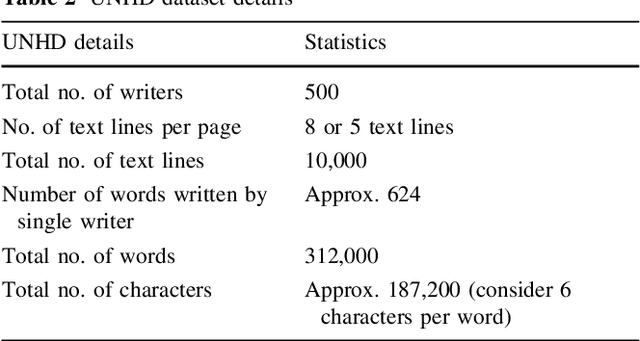
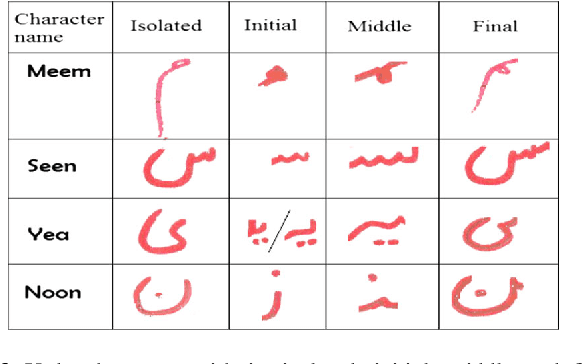
The recognition of cursive script is regarded as a subtle task in optical character recognition due to its varied representation. Every cursive script has different nature and associated challenges. As Urdu is one of cursive language that is derived from Arabic script, thats why it nearly shares the same challenges and difficulties even more harder. We can categorized Urdu and Arabic language on basis of its script they use. Urdu is mostly written in Nastaliq style whereas, Arabic follows Naskh style of writing. This paper presents new and comprehensive Urdu handwritten offline database name Urdu-Nastaliq Handwritten Dataset (UNHD). Currently, there is no standard and comprehensive Urdu handwritten dataset available publicly for researchers. The acquired dataset covers commonly used ligatures that were written by 500 writers with their natural handwriting on A4 size paper. We performed experiments using recurrent neural networks and reported a significant accuracy for handwritten Urdu character recognition.