 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystification of Few-shot and One-shot Learning
Apr 25, 2021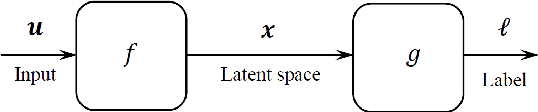
Few-shot and one-shot learning have been the subject of active and intensive research in recent years, with mounting evidence pointing to successful implementation and exploitation of few-shot learning algorithms in practice. Classical statistical learning theories do not fully explain why few- or one-shot learning is at all possible since traditional generalisation bounds normally require large training and testing samples to be meaningful. This sharply contrasts with numerous examples of successful one- and few-shot learning systems and applications. In this work we present mathematical foundations for a theory of one-shot and few-shot learning and reveal conditions specifying when such learning schemes are likely to succeed. Our theory is based on intrinsic properties of high-dimensional spaces. We show that if the ambient or latent decision space of a learning machine is sufficiently high-dimensional than a large class of objects in this space can indeed be easily learned from few examples provided that certain data non-concentration conditions are met.